

こんにちは、ソフトウェアエンジニア兼データサイエンティストの冨田です。
私の所属するフライウィールでは、大企業を含む数多くの企業のデータ利活用を支援しており、その大量のデータを適切に管理・変換・処理することで Conata(コナタ)™ に代表されるようなサービスの提供といった価値を生み出しています。我々のビジネスはお客様からお預かりするデータありきであり、それらのデータを適切に管理するデータスタックの開発にも力を入れています。
今回の記事では、フライウィールが開発しているデータ基盤で使用しているデータスタックについてご紹介します。
フライウィールが取り扱うデータの特色
フライウィールが取り扱うテーブルデータは、主に2つの方法で集められます。
一つは弊社が提供する API や SDK を使用し、顧客企業が抱えるユーザーのデータを直接弊社のサーバーに送信してもらう方法。そしてもう一つは、クラウドストレージ等を介して顧客企業からデータの受け取りを行う方法です。
後者のクラウドストレージ等を介した方法の場合、顧客の事情に合わせた柔軟なデータの受け渡しをサポートしており、受け渡し対象のデータを置くストレージも特定のクラウドに限らず、AWS、Azure、GCP 等の顧客が使用しているクラウドまでデータを取りに行くこともあります。
このような事情から、フライウィールではどのクラウドにデータが置いてあっても同じように処理が可能なマルチクラウド環境を想定したデータ基盤の構築が求められています。
データスタック 概要
フライウィールが採用しているデータスタックの一部をカテゴリ別に図示してみると次のようになります。カテゴリは、モダンデータスタックの文脈でよく使われることの多いカテゴリ名で分類してみています。
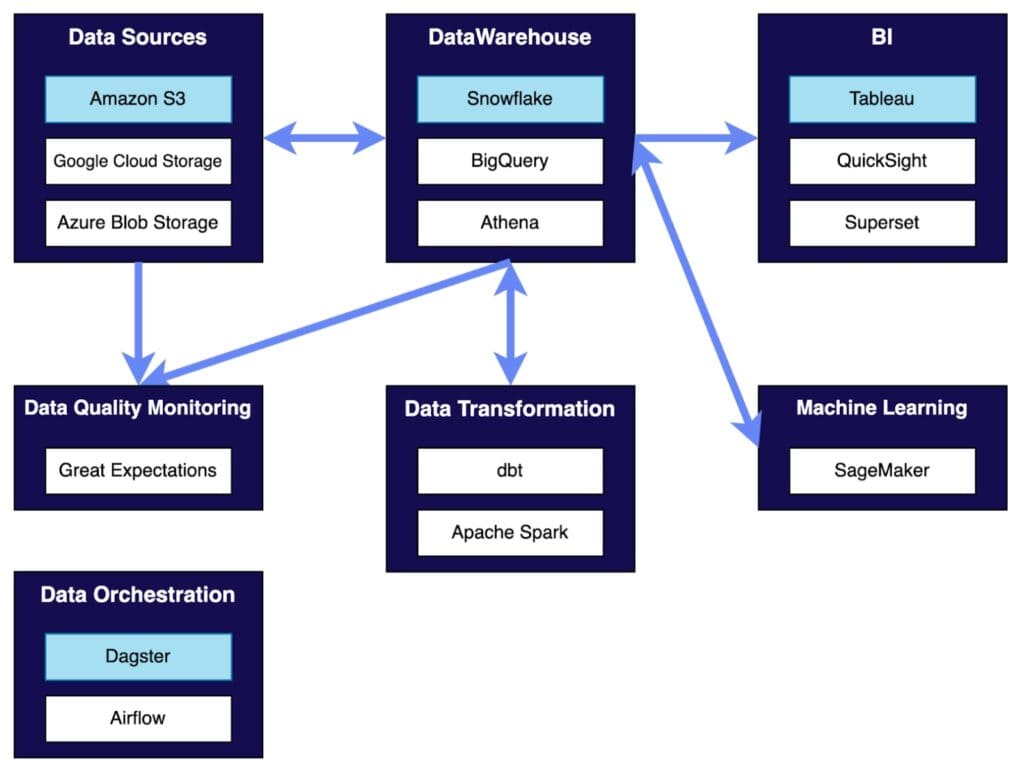
背景色が水色で表示されているサービスについては、社内で標準テックスタックとして指定されていることを意味しており、なんらかの事情がない限りは基本的に標準テックスタックに準拠することが推奨されています。
それぞれの技術がどのような背景で採用され、どのように活用されているかを順番にご説明します。
カテゴリ別の採用技術
Data Sources
顧客企業から受領した生データを保存しておく場所として、フライウィールでは Amazon S3 を採用しています。フライウィールではデータパイプラインや配信サーバーなどを Amazon EKS を活用して管理している Kubernetes クラスタ上で構築しており、同じ AWS により提供されている Amazon S3 は他サービスとの親和性が高いことが主な理由です。
一方で、複数の企業とデータの授受を行い、かつ顧客企業の環境に柔軟に合わせた方法でのデータ授受を行っている弊社のビジネスの性質上、どうしても顧客のデータを AWS 以外の場所に取りに行くことが必要な場合もあります。そのような場合、Google Cloud Storage (GCS) や Azure Blob Storage といったクラウドストレージを使用することもあります。
Storage
処理するデータが集約されるストレージ(データウェアハウス)は、Snowflake を標準として採用しています。Snowflake を採用している最も大きな理由は、マルチクラウドへの対応の容易さが挙げられます。Snowflake を使用すると、Amazon S3 からのデータのロードと Google Cloud Storage からのデータのロードを同じように行うことができ、クラウドの違いを強く意識する必要がありません。
クラウドプロバイダから提供されているデータウェアハウスは、当然ですが自社のクラウド環境下で最も効率よく機能するように作られています。例えば Google BigQuery の場合であれば、BigQuery Omni という機能で S3 や Azure Blob といった他社のクラウドストレージにあるデータに対しても BigQuery で分析が行える機能を提供しています。しかし、2022年4月時点では BigQuery Omni は東京リージョンでは提供されていないのに加え、実際には制限事項があり GCP 上での分析と全く同じことができるかというと、そういうわけではないようです。
また Snowflake にはウェアハウスと呼ばれるクエリを実行するための計算資源のサイズや個数を自由に調整できる機能があり、この機能も非常に有用なものだと感じています。Amazon Athena や Google BigQuery では、同じデータをクエリする他者の影響を受けて、クエリの実行時間が伸びてしまう(または最悪の場合、失敗してしまう)ことなどがあります。Snowflake では定期実行用のウェアハウス、アドホックな分析用のウェアハウス、BIから参照する際のウェアハウスといった形で計算資源を分離し、それぞれに最適な大きさのマシンを割り当てることができるようになっています。
ただし Storage に関しても Data Sources と同様、顧客企業やプロジェクトの制約によっては Google BigQuery や Amazon Athena といった別のサービスを使用する場合もあります。
Data Transformation
データウェアハウスにロードされたデータの変換には dbt や Apache Spark を活用しています。
dbt は大まかに説明するとデータ変換を行う SQL を管理するためのツールで、テンプレートやテスト、自動生成のドキュメントなどでデータ変換の手助けをしてくれます。過去に dbt とは何をするツールなのか? という記事を公開していますので、dbt というツールの概要についてはそちらの記事をご参照ください。
Apache Spark は SQL では対応できないようなデータ変換や、Spark の MLlib という機械学習ライブラリを活用した変換を行いたい場合に利用しています。
ソフトウェアエンジニアリングでいうところの単体テストに相当するようなテスト、つまり SQL のクエリや Spark で記述した変換ロジックのテストは、この Data Transformation のカテゴリでカバーすることが望ましいです。Spark であればコードなので通常の単体テストは書きやすいですし、dbt も SQL のテストがサポートされているので、NULL を許容しないカラムに NULL が入っていないか、JOIN の前後で行数が意図せず増減していないかといった、間違った SQL を書いていないかといった簡単なテストを記述することができます。
BI
フライウィールではデータの分析結果をダッシュボードという形で可視化し、社内で活用したり社外の顧客企業に提供したりすることが頻繁に行われており、その際の BI ツールとして Tableau を主に活用しています。
Tableau は接続できるデータソースや可能な分析・可視化の幅が広く、柔軟な分析を素早く行えることが魅力です。一方で、ダッシュボードを複数人で同時に開発したり、コードでしっかり管理して変更のレビューをしたり履歴を追跡する、といったことは苦手としている分野です。Looker など他のサービスではダッシュボードを git 等でのバージョン管理できるものが出てきており、そのようなサービスは複数人での開発はより効率的に行える印象です。ただし、良くも悪くもデータソースなどをコードで書いて管理する必要があるため、手元のサンプルのエクセルファイルから短時間で素早くインサイトを得る、といった動きは Tableau を採用する大きな利点かと思います。
レビューがしづらい点や git 等でのバージョン管理がしづらい問題については、Tableau Document API を利用してワークブックやデータソースの内容を人間が読める形式のファイルで出力するツールを開発し、その出力ファイルもコード管理・レビューすることで緩和しようとしています。
最初の図でも示したとおり、BI ツールとしては Amazon QuickSight や Apache Superset も活用しています。Tableau の場合はアカウントの発行が必要になるので、顧客企業の多数の社員に向けて公開するダッシュボードや、フライウィール社内でのみ活用されるダッシュボードでこれらの BI ツールが使用されています。
Machine Learning
データウェアハウスに保存されたデータに対して分析や機械学習の実験を行う環境として、Amazon SageMaker Studio を活用しています。社内でよく使われるライブラリがインストールされた状態の Docker イメージを用いてインスタンスを立ち上げることができるようになっており、余計なセットアップなくクラウド環境で実験を始めることができるようになっています。
Data Quality Monitoring
データ品質のテストには Great Expectations の採用を進めています。Great Expectations はデータに対するテストを行うためのツールで、データに対して Expectations と呼ばれる”データがあるべき姿” を定義し、実際のデータが Expectations に合致しているかどうかをテストします。
Expectations は様々なものが実装・公開されており、 “user_id が NULL でない” といった単純なテストから、”今日の購入金額の分布が昨日の分布と比較し大きく変わらない1” といったデータ品質をテストするような Expectations も用意されています。
Data Orchestration
データ変換の前後も含めたワークフロー管理には Dagster を採用しています。弊社は以前は Apache Airflow を使用していましたが、プロジェクトの成長や関係者の増加に伴い、下記のような使いづらい点が目につくようになってきました。
- ローカル環境での開発が難しい
- チーム・プロジェクトごとの環境の分離が難しく、他チームとのリリースタイミングの調整が必要になる
- DAG のテストが書けない・書きづらい
- Web UI の認証が不安定・Web UI があまり直感的でない
Dagster では Moving past Airflow: Why Dagster is the next-generation data orchestrator で説明されているように Airflow で使いづらい点を解消されるような方針で開発されており、弊社でも正式に導入を決定しました。
運用を通して得られた知見(の一部)
上記の採用技術紹介では触れることができなかった、このデータスタックを運用する中で見えてきた知見の一部を共有します。
Snowflake と dbt の管理
複数の顧客のデータを預かっていく上で、どのように Snowflake や dbt の管理をしているかを簡単にご紹介します。my_project という仮想のプロジェクトの簡単な構成図を元に説明します。
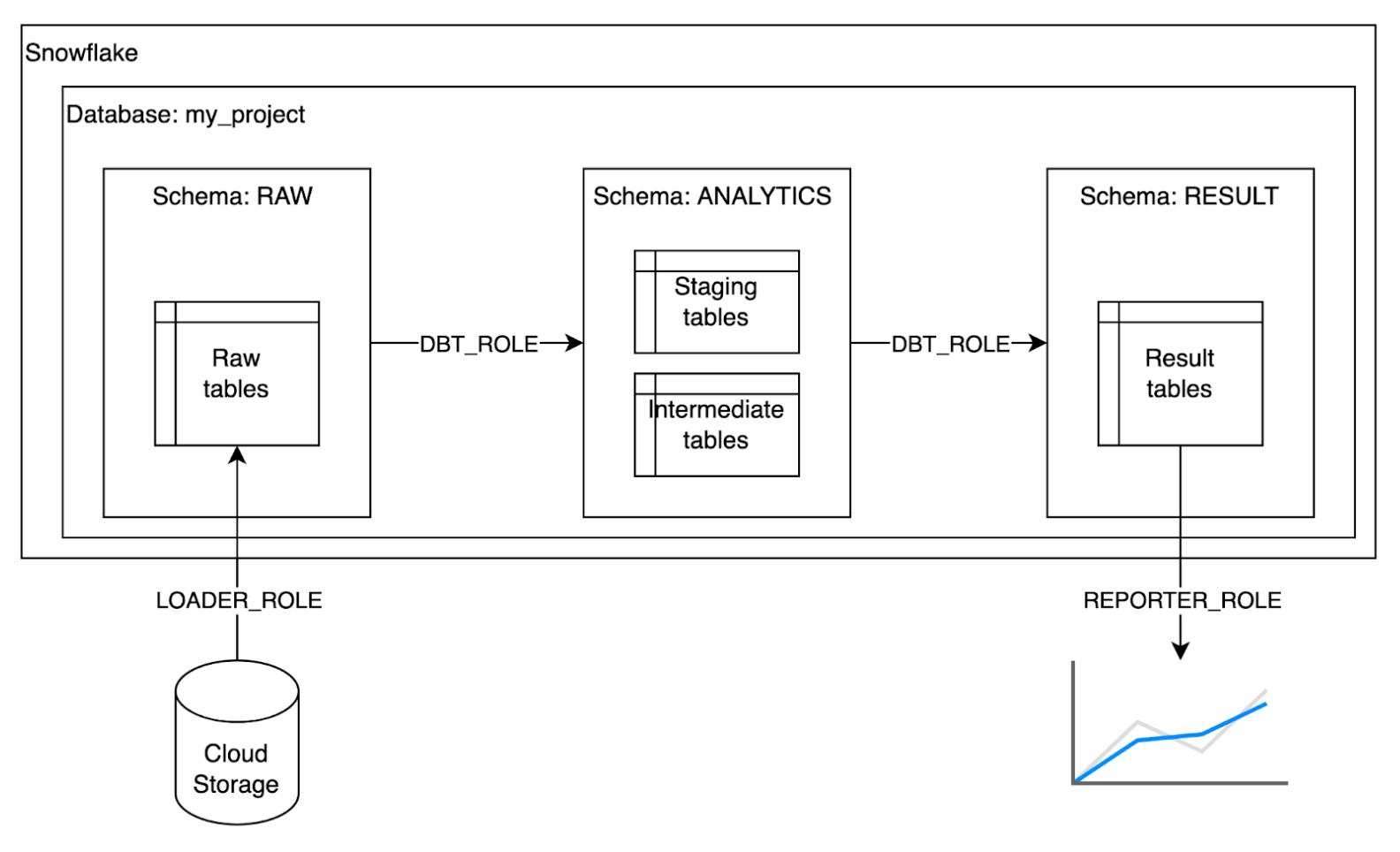
まず、フライウィールではプロジェクトごとに異なるデータベースを用意しています。例えば今回の my_project であれば MY_PROJECT という名前のデータベースを用意します。
各データベースの中には、RAW、ANALYTICS、RESULT という3つの異なるスキーマを定義しています。これは dbt Labs の How we structure our dbt projects という記事に定義されている下記の3つのモデル構成を意識したものです2。
- RAW: 顧客から受領したデータ、自社で収集したデータの生データをそのまま保存する場所
- ANALYTICS: staging と呼ばれる前処理を行ったデータや、中間テーブル等を保存する場所
- RESULT: 最終的な集計結果など、BIツールや機械学習など下流の処理から詐称されるテーブルを保存する場所
それぞれのスキーマを読み書きできる権限は異なるロールを用意して管理されています。図には主なロールを3種類図示してあり、それぞれ次のような権限を持っています。
- LOADER_ROLE: 生データを Snowflake にロードするときに使用するロールで、RAW スキーマに対する読み書きの権限のみをもつ
- DBT_ROLE: dbt によるデータ変換に使われるロールで、RAW スキーマからの読み出し権限、ANALYTICS/RESULT スキーマへの読み書きの権限をもつ
- REPORTER_ROLE: Tableau 等の BI ツールにて使われるロールで、RESULT スキーマからの読み出し権限のみをもつ
このようにすることで、生データをロードする人は変換後のデータを触ることができなかったり、BIを使う人は必要のない中間テーブルなどを見ることができないようになっています。
また図では示していませんが、
- 開発環境、テスト環境、本番環境のスキーマレベルでの分離
- ロード用、データ変換用、BI用といった用途ごとのウェアハウスの用意
といったことも行っています。
データに対するテストの使い分け
dbt と Great Expectations は、両者ともデータに対するテストをサポートしており、一見するとどちらでどのようなテストをすべきかが分かりづらいです。
実際、両者は例えば NULL チェックと言った基本的なテストはどちらでも実施できますし、dbt_expectations という Great Expectations の Expectations を dbt パッケージとして移植したものも存在しており、どちらのテストに頼るべきか判断に迷う方もいるかと思います。
ここからは一部フライウィールとしての見解ではなく私個人としての見解も混ざりますが、基本的には以下のような方針でテストの棲み分けをすると良いと考えています。
基本方針
dbt は SQL3を開発しながら繰り返し実行されるようなテストを記述し、Great Expectations には本番データを対象に Data Orchestration ツール (Dagster, Airflow 等) を介して実行されるテストを記述する。
dbt で書くべきテスト
dbt でのテストは SQL の開発時に繰り返し実行されることが想定されます。また、開発の際には本番環境のデータとは異なるデータを用いていることも多いです。
上記のような理由から、dbt では本番環境のデータ品質を確認するようなテストではなく、実行時間が比較的短時間で済み、開発用のデータに対して繰り返し実行される単体テストを記述することが良いと考えています。
具体例をあげると
- 指定のカラムに NULL が存在しないことを確認する not_null
- 主キーに重複が存在しないか確認する unique
- カラムに意図せぬ値が含まれていないか確認する accepted_values
- 結合に使用するキーに不整合がないか確認する relationships
といった dbt 標準のテストに加えて、dbt-utils というパッケージの
- JOIN を行う前後のテーブルで行数が変化していないか確認する equal_rowcount
- 指定カラムの組み合わせがユニークになっているかを確認する unique_combination_of_columns 4
などは単体テストに相当するテストとして dbt でカバーすると良いと思います。
Great Expectations で書くべきテスト
本番データを対象にしたデータ品質に対するテストは Great Expectations で書くのが良いと思います。Great Expectations を使うべき理由としては、本番データを使用する品質テストは時間(とお金!)がかかることから極力開発時に何度も実行することは避けたいことや、弊社の場合は SQL 以外にも入出力となる CSV 等のファイルに対してもテストを行いたいケースがあることが挙げられます。
また Great Expectations は Data Docs と呼ばれるデータの品質テストの結果をまとめたレポートを出力する機能があり、これらを保存しておくことで過去の本番データの品質を手軽に見返すことができる、といった利点もあります。
品質テストというのがどのようなものか、仮想の具体例を用いて考えてみます。とある実店舗に対して最適な在庫数を算出し、最新の在庫数との差分を自動で発注するようなプロジェクトを考えます。例えば仮に最適な在庫数を算出するロジックが、全体的に想定よりも大きな数値を出力してしまったとします。最適在庫数の推定ロジックにバグを埋め込んだ、入力となるデータに間違いがあった等、最適在庫数は様々な理由で予想外の挙動をする可能性があります。
このような事態が発生した場合、仮にテストが行われていないとその想定よりも大きな値に基づいて自動的に在庫の発注がかかり、発注量によっては実店舗に大きな損害が発生してしまうこととなります。Great Expectations を使って、「今日の発注予定数の分布と昨日の発注数の分布の KL ダイバージェンスがしきい値以下である (= 似たような形をしている)」といったテストを入れておくと、一定程度以上分布が異なっている場合にはアラートを鳴らして本当にその数字通り発注して良いのかのチェックを入れることができます。
上記のようにデータの品質による事故を事前に防ぐことができるため、入力となるデータや出力となる機械学習モデルの予測値などの統計値・分布などはできる限り Great Expectations でテストするのが安全かと思います。
まとめ
本記事ではフライウィールのデータスタックについて、採用している技術とそこから得られた知見等を紹介しました。特に dbt x Snowflake などは最近盛り上がっているものの日本語での情報はまだまだ少なく、Great Expectations に関してはより情報が少ないのが現状です。データのテストなどは非常に大切な分野だと思うので、本記事が少しでも日本の皆様の参考になると幸いです。
また、この記事では2022年4月時点でのデータスタックを紹介していますが、これは今後も必要に応じて変更が加えられていくと思います。実際、今回紹介した中でも Snowflake、Dagster、dbt、Great Expectations はこの1年で検証や導入が進められてきたサービスであり、そこからも弊社のデータプラットフォームが日々進化しているのを感じてもらえるのではないかと思います。
まだ弊社もこの構成での運用歴が長いわけではありませんし、記事中でも言及している通り歴史的経緯や顧客の都合等でまだこのデータスタックに則っていないプロジェクトも多数存在しています。今回紹介したデータ基盤自体の改良や、既存プロジェクトへの標準技術の導入、またデータ基盤上での分析や機械学習モデルの構築など、弊社としてはやりたいことがまだまだあるのですが全然人手が足りていない状態です。フライウィールではソフトウェアエンジニアやデータサイエンティストを積極的に採用していますので、本記事でフライウィールが開発するデータ基盤に興味を持ってくださった方は、ぜひまずはカジュアルにお話を聞きに来てみてください!
Notes
1. 指定のカラムの分布を昨日と今日で比較し、KLダイバージェンスがしきい値以下であることを確認する、といったことができる。↩
2. 社内の事情により名称は変更されていますが、RAW が Sources、ANALYTICS が Staging Models、RESULT が Marts models に対応する概念です。↩
4. サロゲートキーなどをハッシュで割り当てるときに、もととなるフィールドに同じものが存在しないかをテストできる。↩
Author: 冨田 恭平(フライウィール ソフトウェアエンジニア)
2018年フライウィール入社。パーソナライズプラットフォーム Conata(コナタ)™のレコメンドや検索のテックリードを担当。データ分析環境の整備や、データ分析・可視化・モデル開発などにも携わる。以前、マイクロソフトではAI and Research Groupの「りんな」にて対話型AIを開発。