

こんにちは、ソフトウェアエンジニアの冨田です。
弊社では一部のプロジェクトで dbt (data build tool) の導入を始めました。私が初めて dbt を学んだときの感想は「結局何をしてくれるものかわからない」「何が嬉しいかよくわからない」といったものでした。dbt に少し触れ、同じ感想を抱いている方は多いのではないでしょうか。
本記事では dbt に興味があるがどんなツールか具体的にイメージできない読者を対象に、dbt が Modern Data Stack で果たす役割や dbt が行う処理の中身について紹介したいと思います。
なお、本記事は主に dbt CLI に焦点を当てて紹介しており、dbt Cloud 特有の機能や特徴については説明をしていません。
dbt とは何か?
Modern Data Stack における位置づけ
dbt 自体の説明をする前に、近年広がってきている Modern data stack という考え方と、その中での dbt の位置づけについて説明します。
Fivetran のブログ記事によると、modern data stack とはデータ統合を実現するためのツール群のことです。近年のクラウドでホストされているデータ分析環境を想定しているなどの特徴があるようです。詳細は元記事を参照していただくとして、実際にどのようなツールが modern data stack に含まれているかが Snowplow のブログ記事で紹介されています。この記事に掲載されている “The Modern Data Stack” という図には2021年時点で各カテゴリにどのようなツール・サービスが存在しているかが非常に良くまとめられています。
Snowplow の図によると dbt は “processing” というカテゴリに分類されています。このカテゴリでは、データレイクやデータウェアハウスに保存されているデータを処理・変換し、結果をデータウェアハウスに書き戻す役割を担っています。dbt もまさに同じ役割を担っており、データウェアハウスに保存されているデータを変換してデータウェアハウスに書き戻す部分で使用するツールとなります。
ELT の “T”
dbt の位置づけを、ELT (Extract, Load, Transform)1の “T” を担当するツールであるという説明もなされることがあります。
dbt はあくまでデータ変換だけを実行するツールであり、データを Amazon Redshift, Google BigQuery, Snowflake などのデータウェアハウスに保存するまでの “E” と “L” の部分は他のツールに任せ、そこから先のデータ変換を dbt が行うことになります。
実際のところ dbt は何をするのか?
では具体的に dbt はどのような動作をしてデータ変換を行うツールなのでしょうか?dbt の開発者である Tristan Handy による “What, exactly, is dbt?” によると、dbt はテンプレート化された SQL のコンパイルと SQL の実行という2つの基本的な役割2を持っています。
テンプレート化された SQL のコンパイル
dbt ではデータ変換を SQL の SELECT 文で記述するのですが、通常の SQL とは異なり Jinja を使ってテンプレート化された SQL を使用します。このテンプレート化された SQL を実行可能な SQL にコンパイルするのが dbt の1つ目の役割です。
SQL を実行しデータウェアハウスに実体を作成
2つ目の役割はコンパイルされた実行可能な SQL をデータウェアハウスに対して実行し、テーブルやビューなどの実体を作成することです。テンプレートを使用して SQL を記述する際にテーブル間の依存関係を定義することができ、その情報を用いることで1つのコマンドでテーブル間の依存関係を考慮してデータ変換を行いテーブル・ビューを作成してくれます。
簡単な例の紹介
テンプレート化された SQL がどのようなものか、チュートリアルで用いられている例を簡略化して紹介します。
顧客の注文情報のモデル3である stg_orders.sql4 という既存のモデルから、注文を顧客ごとに集計した customer_orders.sql というモデルを次のテンプレート化された SQL で定義したとします。
with orders as (
select * from {{ ref('stg_orders') }}
),
customer_orders as (
select
customer_id,
min(order_date) as first_order_date,
max(order_date) as most_recent_order_date,
count(order_id) as number_of_orders
from orders
group by 1
)
select * from customer_orders{{ }} で囲まれている箇所がテンプレート化されている箇所で、この例だとwith句に含まれている {{ ref(‘stg_orders’) }} 以外は通常の SQL で記述されています。ref というのは dbt により用意されているマクロで、モデル間の依存関係を記述するのに利用します。
ref での参照はコンパイル時に解決され、コンパイル後の SQL ではデータウェアハウス上での実際のテーブル名やビュー名5に置き換わっています。また、dbt はこの ref から customer_orders の計算には stg_orders が必要、という依存関係も理解することができます。今回は簡単な例ですが、複雑なデータ変換だと SQL の実行順番を間違えないようにドキュメントを確認しながら実行する・・・という経験のある方もいるかもしれませんが、ref で依存関係を定義しておくとクエリの実行順序は dbt が管理してくれます。
dbt を導入するメリット
公式ドキュメントにも記載されている通り、SQL のコンパイルと実行以外にも、様々な利点があるのですが、その中でもドキュメンテーションとテストの2点は開発上のメリットが大きいように思います。
ドキュメンテーション
データを扱うプロジェクトでは、データ分析やモデリングを行う人が各々データウェアハウスやデータマートに自由にテーブルを作成し、結果として生成方法も用途も把握できないテーブルが大量に生成されている、という状況はあるあるなのではないかと思います。
dbt には SQL 中に記述されているモデル間の依存関係6を把握し、各モデルのスキーマやデータリネージを含むドキュメントを自動で生成する仕組みがあります。その結果、少なくともテーブルの生成方法に関しては SQL を書いた本人でなくてもデータ変換過程が追跡可能になることが期待されます。
下記画像は公式ドキュメントから引用した自動生成されるドキュメントのサンプルです。左側のメニューにプロジェクトで定義されているモデルの一覧、中央にモデルの説明文やカラムの定義、そして右側にデータリネージが可視化されています。
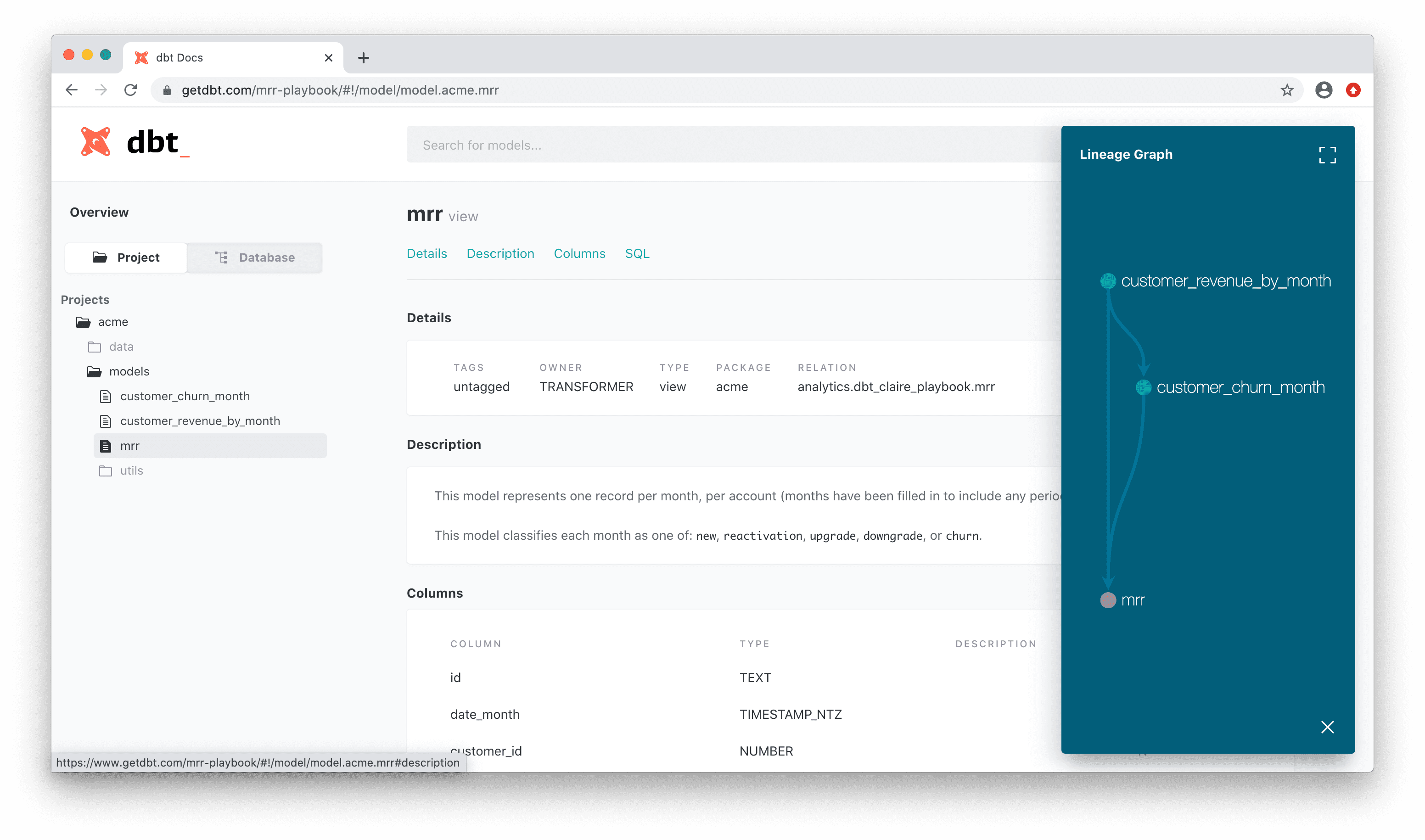 (引用元: https://docs.getdbt.com/docs/building-a-dbt-project/documentation#overview )
(引用元: https://docs.getdbt.com/docs/building-a-dbt-project/documentation#overview )
テスト
データに対するテストの定義・実行をする仕組みが用意されています。例えば「このフィールドに NULL が値として入っていないか」「ユニークであるべきフィールドに重複する値が存在していないか」等のテストができます。
他に期待している点
また社内で dbt について会話していると、ドキュメンテーションとテスト以外にも次のような点でもメリットがあるのでは、との声がありました。
- 個々のモデルでは1つの変換に注力するようにすると、よくありがちな “とても複雑な SQL クエリ” を回避できるのではないか。従来は細かく中間テーブルを materialize 7 するのは現実的ではなかったが、dbt ならできそう。
- モデルを使い回すことができるのでクエリの記述量が減少し、間違いも減りそう。
- 異なるデータに適用できる汎用的な処理はマクロやパッケージとして共有することで、データ分析に関する知見を社内で共有できそう。
気になる点
上記で紹介した以外にも、世の中では大小さまざまなメリットが紹介されていますが、まだ発展途上の技術ということもあり、気になる点もいくつかあります。
AI/ML との統合
SQL で処理ができるデータ変換に関しては dbt は非常に優秀なのですが、現時点で実務で使うとなると SQL では対応しきれない処理をどう扱うかに難しさを感じるのではないかと思います。
例えば、以下のような機械学習を活用した処理は広く行われているものではないかと思いますが、dbt だけで実装することは容易ではなさそうです。
- 購入ログを参照して、商品の売上予測モデルを学習する
- 商品マスタに登録されている商品に対して、売上予測モデルを適用して売上予測値を得る
- 商品マスタに売上予測値のカラムを追加したテーブルをデータマートに保存する
このような過程で使われる機械学習モデル (上記の例だと売上予測モデル) は Spark で実装されているかもしれませんし、Tensorflow や PyTorch といった深層学習のフレームワークを使って実装されているかもしれません。このように、データウェアハウス内のデータ変換が SQL では済まないような場合に、現時点では決定的な回答はまだ用意されていないように思います。
例えば Modern Data Stack: Which Place for Spark? という記事では、多くの企業が提案している Modern Data Stack には Spark が含まれていないと指摘しています。クラウドデータウェアハウスには Spark の DataFrame API に似た機能を提供しているものも存在する (例えば Snowflake の Snowpark) のですが、Spark MLib に実装されているような実装済みモデルを使えるような世界にはまだ到達していません。
まだ簡単には代替できないので Spark をそのまま使うことになるのですが、現時点で Spark によるデータ変換を中間に置きたい場合は SQL 部分を dbt、Spark 部分を Airflow/Dagster のようなオーケストレーションツール等8を利用する必要がでてきます。
dbt にも機械学習を使えるようにしようという試みの中で、私が調べた中で最も可能性がありそうだと感じたのは dbt と BigQuery ML との組み合わせです。使用できるモデルは BigQuery ML でサポートされているものに限られてはしまいますし、料金も少し多めにかかってしまうかもしれませんが、機械学習モデルの学習と推論が SQL から実行可能なので、dbt にもそのまま使うことができます。興味のある方は、この英語の記事9などで詳細を見ていただければと思います。
BigQuery ML では任意の TensorFlow モデルをインポートして推論に使用することができます。任意の TensorFlow モデルの学習は行えないようなので、まだ dbt の範囲内で何でもできるというわけではないですが、BigQuery ML が進化してサポートするモデルが増えていったり、他社のデータウェアハウスも追随していくと、dbt と機械学習モデルの親和性が高くなっていくのかもしれません。
また、Continual のように、既存のデータウェアハウスや dbt と連携して予測モデルの学習と推論が行えるようなサービスを開発している企業も出てきています。Spark で自由に処理をするほどの自由度はないですが、指定したカラムの値を予測するモデルを構築する、というような機械学習モデルであれば、このようなサービスを活用すると dbt との連携もスムーズなのかもしれません。
IDE
Google BigQuery や Snowflake といったクラウドベースのデータウェアハウスの多くにはウェブブラウザで使用できるリッチな UI が用意されており、クエリを書く際にエディタの補完やフォーマッタなどの機能を利用している方も多いかと思います。dbt を使用する場合は Jinja + SQL で記述することになるので、元のデータウェアハウスのエディタをそのまま使用することはできません。
Fivetran が Visual Studio Code 向けの dbt Language Server の開発を進めていたりもするようですが、2022年2月現在で同拡張機能はプレビュー状態で、 BigQuery にのみ対応しています。
基本概念: Model と Materialization
次は一歩踏み込んで、dbt の “Model” と “Materialization” という概念について説明します。
Model はデータ変換を1つの SELECT 文で記述した SQL ファイルのことです。先述の通りこの SQL はテンプレート化されており、マクロ等を使用して通常の SQL よりも柔軟な記述もできます。
Model で定義された SELECT 文を実行した結果を、どのようにデータウェアハウスに保存しておくか指定する方法を materialization と言います。Model には必ず1つの materialization が指定されており、dbt run コマンドで SQL を実行すると、指定された materialization に従ってデータウェアハウスに実体が生成されます。例えば table という materialization を指定すると、SELECT 文の結果がデータウェアハウスのテーブルとして保存されることになります。
4つの materialization
Materialization には table, view, ephemeral, incremental という4種類が存在します。dbt に初めて触れる方は、特に後半2つの挙動が想像できないこともあると思いますので、それぞれ dbt run で SQL を実行したときに何が起こるかを簡単に紹介します。
table
SELECT 文の実行結果をテーブルとして保存します。テーブルは毎回作り直されます。
view
SELECT 文をビューとして保存します。ビューは毎回作り直されます。
ephemeral
SELECT 文、およびその実行結果はデータウェアハウスには保存されませんが、他のモデルから参照することはできます。Ephemeral を指定したモデルは、それを参照するモデルのコンパイル後の SQL に WITH句として挿入されます。
incremental
SELECT 文の実行結果をテーブルとして保存しますが、テーブルを全て作り直すことはせず、前回実行時との差分に対してのみ INSERT/UPDATE を行います。
“前回実行時との差分” は is_incremental() というマクロを指定して自由に定義できます。詳しくは Filtering rows on an incremental run を参照してください。
dbt の”前後”
dbt を実際のプロダクトで使用する際には、必ず dbt の “前後” の処理が必要になってきます。前に関してはデータを何らかの形で集めてきてデータウェアハウスに保存する作業 (ELT の “E” と “L”) が必要になりますし、変換したデータはBIツールで可視化されたり機械学習に活用されることも多いかと思います。
このように dbt の前後の処理と dbt をまとめて1つのワークフローとして管理するために、Airflow や Dagster といったデータオーケストレーションツール (data orchestration tool) が必要になります。弊社でも Airflow や Dagster を採用して dbt との連携を模索していますので、また機会がありましたらその取組についても共有させていただきます。
おわりに
本記事では dbt の Modern data stack の中での位置づけや、具体的な役割、model や materialization といった dbt の基本概念などを紹介してきました。
dbt は比較的新しい技術で、弊社もまだ試行錯誤しながら導入している段階で、まだまだやるべきことがたくさんあります。このような新しい技術も取り入れた、モダンなデータプラットフォームを一緒に作ってくれるソフトウェアエンジニアを積極採用中ですので、少しでもご興味のあるかたはまずは気軽に話を聞きに来てみてください!
References
- What Is the Modern Data Stack? | Blog | Fivetran
- The modern data stack in 2021
- The Modern Data Stack Ecosystem: Spring 2022 Edition
- Modern Data Stack: Which Place for Spark ? | by Furcy Pin | Jan, 2022
- Dagster and dbt: Better Together
Notes
1.従来の ETL (Extract, Transform, Load) とは順番が違う点に注意。ELT ではクラウドデータウェアハウスに Load した後に、クラウドのパワーを駆使して Transform を行います。↩
2. dbt CLI では `dbt run` というコマンドでコンパイルと SQL の実行が両方行われます。↩
3. “モデル”は dbt で使われるときには明確な定義があります。詳細は「基本概念: “Model” と “Materialization”」で説明します。↩
4. orders.sql ではなく std_orders.sql となっているのは、Best practicesや How We Structure our dbt Projects で紹介されている通り、生データへの直接のアクセスはできるだけ避け、生データを参照する staging models を用意することが推奨されているためです。↩
5. 後述の ephemeral という materizalization の場合は、テーブル名やビュー名ではなく WITH 句が追加される。↩
6. https://docs.getdbt.com/reference/dbt-jinja-functions/ref/ ↩
7. materialization については後の章で説明しています。 ↩
8. 先の記事では “dbt for pySpark” に相当するものを自社開発したと紹介されています。↩
9. https://towardsdatascience.com/agile-machine-learning-with-dbt-and-bigquery-ml-c067431ef7a9 ↩