

データサイエンティストの川端です。10月よりフライウィールにジョインして、データ基盤開発やデータ分析・可視化、広告配信ロジックの開発などを主にやっています。
FLYWHEEL Advent Calendar 2019 の16日目は、その中で取り組んでいるデータ分析・可視化のためのデータ基盤で用いたHyperLogLogの活用について紹介できればと思います。すでにHyperLogLogについてや、その近似精度、計算コストの実験については過去に多くのブログが書かれているので、本稿ではHyperLogLogのコアであるsketchの便利さを中心にどれだけ実戦で使えるかに主眼を置いて紹介していきます。
Count-distinct problem(異なり数集計の問題)
WebサイトのPV(page view)数や商品の売上金額などは単純に数を足し上げれば集計できるためそこまで大きな計算コストは掛かりません。それに比べて、Webサイトのユニークな訪問者数(UU数)など異なり数を集計するためには、UU数に比例するメモリを必要とし大規模なデータに対しては非常に大きな計算コストが掛かってきます。
また、PV数などは先週のPV数と今週のPV数を足し合わせることで直近2週間分のPV数を集計できますが、UU数は同じ様に足し合わせることができず直近2週間分のデータを使って再度集計する必要があります。そのため、例えば日次の中間テーブルで集計されたUU数はその中でしか使えず汎用的に利用することができません。
これらの問題を解決するために低コストで異なり数を推定する方法が様々考えられており、その中で最もよく使われているのがHyperLogLogというアルゴリズムです。
HyperLogLogの直感的な理解

HyperLogLogは乱択アルゴリズムと言われる乱数の確率を利用したものになります。アルゴリズムの詳細は本稿の主旨ではないので、下の参考ページを参照してもらうとして、ここでは直感的な理解だけを説明します。
ユーザごとにコイントスを8回してもらい表の場合は0、裏の場合は1として、最初から0が連続した回数を求めます。そして、それの最大値だけを記録しておきます。全員のコイントスが終わったあとに、最初から0が連続した回数の最大値が下図のように4回だっとします。その場合、この事象が起こる確率は1/2の4乗の1/16で、この確率が観測されたということは16人ぐらいがコイントスをしたのではと期待されます。

一般化すると、最初から0が連続した回数の最大値がkだったとすると、2のk乗の異なり数なのではと推測でき、これがHyperLogLogの基本原理です。このとき、異なり数の推定に必要なものは最初から0が連続した回数の最大値kであり、これだけを記録しておけばよく、これをsketchと呼びます。どれだけ異なり数が増えようがこのsketchを記録しておく分のメモリしか消費しないのでかなりの低コストで異なり数を推定することができるというわけです。
また、sketchは並列計算可能で、例えば上図の例だと上から5人ずつ3グループに分けて3つのsketchを計算し、その3つのsketchの最大値を計算すると元の15人のsketchと一致します。この性質のおかげで再利用性が増し本当に使い勝手のよいデータ構造とアルゴリズムだと思います。
もちろんこれだけだと、2のk乗(2, 4, 8, 16, 32, …)の異なり数しか推測できないとか、異なり数が少ないときには確率的に精度が低いなど問題があるので色々な工夫がなされています。詳しくは、こちらを。
- https://engineering.fb.com/data-infrastructure/hyperloglog/
- http://blog.brainpad.co.jp/entry/2016/06/27/110000
- https://stefanheule.com/papers/edbt13-hyperloglog.pdf
HyperLogLogの真価はsketchにある
sketchを再利用しやすい粒度で定期的に作っておくと、低コストで柔軟に様々な異なり数を推定でき可視化・分析の効率が飛躍的に向上します。
- sketchをマージすることで複数の集合を合わせた集合(union)の異なり数が推定できる。
- 日次→週次、月次
- webページごと→webサイト全体
- 性別・年代ごと→男性だけ、女性20~40代など
- 異なる集合の積集合(intersection)の異なり数も推定できる!
- アクセスログと、ユーザ属性のマスタデータのそれぞれのsketchから共通集合の異なり数を推定
実際にやってみましょう!
Let’s Try
今回は、 AWSのAthenaを使って実験をしますが、様々なデータベース(BigQuery, redisなど)にHyperLogLogは実装されていますので適宜置き換えて使ってみてください。実験には本稿用にログの量を調整し、一日だいたい2億件のレコード数が含まれるユーザの行動ログを用います。
1. ワンショットでの異なり数の集計
count distinct
SELECT
count(distinct user_id)
FROM event_log
WHERE event_date between '2019-11-01' and '2019-11-30'結果:139,258,966
計算リソース:Run time: 42.02 seconds, Data scanned: 91.62 GB
HLLによる推定値
SELECT
approx_distinct(user_id)
FROM event_log
WHERE event_date between '2019-11-01' and '2019-11-30'結果:138,340,970(誤差-0.66%)
計算リソース:Run time: 19.59 seconds, Data scanned: 91.62 GB
ワンショットの集計で使った場合、計算時間が半分以下になっており、データサイズが大きくなるほどにその効果が大きく感じられると思います。
ただし、これだと毎回集計するためのData Scanned Sizeは変わらず、Data Scanned Sizeに応じた課金であるAthenaやBigQueryではあまり嬉しくありません。HyperLog Logの真価はsketchの活用にあると思います。
2. HLL sketchを用いた和集合(Union)の異なり数集計
事前にsketchを必要最小粒度で集計して中間テーブルとして保持しておくと、その中間テーブルを使って様々な異なり数の集計が可能になります。例えば、day_level_aggregateというテーブルに日にちとdim1, dim2という粒度でグルーピングしてsketchを作っておきます。
INSERT INTO day_level_aggregate
SELECT
event_date,
dim1,
dim2,
CAST(APPROX_SET(user_id) AS VARBINARY) AS hll_sketch
FROM event_log
WHERE event_date between '2019-11-01' and '2019-11-30'
GROUP BY 1, 2, 3計算リソース :Run time: 37.47 seconds, Data scanned: 92.04 GB
このsketchを使って1.と同じ11月のユニークユーザ数を計算してみます。
SELECT
CARDINALITY(MERGE(CAST(hll_sketch AS HYPERLOGLOG)))
FROM day_level_aggregate
WHERE event_date between '2019-11-01' and '2019-11-30'結果:141,154,905(誤差1.4%)
計算リソース:Run time: 1.97 seconds, Data scanned: 171.46 KB
計算時間は42秒→2秒、Data scanned sizeは92G→200Kと圧倒的なパフォーマンスで近似値を計算することができています。これだけでも相当嬉しいのですが、sketchを必要最小粒度で集計しておくと、あとから必要な粒度に色々と変えて異なり数を計算することができることが非常に素晴らしい思います。それではついでに、日毎のユニークユーザ数も計算してみます。
SELECT
event_date,
'count distinct' as type,
count(distinct user_id) as uu
FROM event_log
WHERE event_date between '2019-11-01' and '2019-11-30'
GROUP BY 1, 2
UNION ALL
SELECT
event_date,
'HyperLogLog' as type,
CARDINALITY(MERGE(CAST(hll_sketch AS HYPERLOGLOG))) as uu
FROM day_level_aggregate
WHERE event_date between '2019-11-01' and '2019-11-30'
GROUP BY 1, 2結果と誤差はこんな感じでした。デフォルトでは標準誤差は2.3%になっており、approx_distinct(x, e)やapprox_set(x, e)の関数のパラメータeで標準誤差を[0.0040625, 0.26000]の範囲で任意に設定することも可能です。
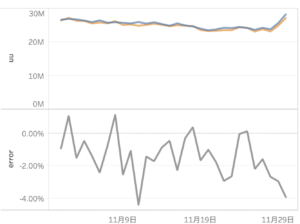
もう少し複雑な、特定の期間(11/10 ~11/25)の平日(weekday)と週末(weekend)ごとのdim2で分けられたユニークユーザ数もsketchから計算できます。
count distinct
SELECT
CASE WHEN dow(from_iso8601_date(event_date)) IN (6, 7) THEN 'weekend' ELSE 'weekday' END as dow,
dim2,
count(distinct user_id)
FROM event_log
WHERE event_date between '2019-11-10' and '2019-11-25'
GROUP BY 1, 2計算リソース:Run time: 41.24 seconds, Data scanned: 46.74 GB
hll sketch
SELECT
CASE WHEN dow(from_iso8601_date(event_date)) IN (6, 7) THEN 'weekend' ELSE 'weekday' END as dow,
dim2,
CARDINALITY(MERGE(CAST(hll_sketch AS HYPERLOGLOG))) as UU
FROM day_level_aggregate
WHERE event_date between '2019-11-10' and '2019-11-25'
GROUP BY 1, 2計算リソース:Run time: 3.18 seconds, Data scanned: 172.69 KB
結果:
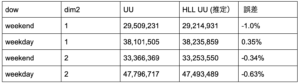
誤差も少なく素晴らしいパフォーマンスです!
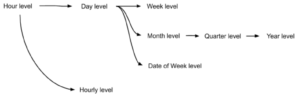
時間軸の必要最小粒度として、時間単位(Hour level)で中間テーブルを作成してsketchを保持しておくのがおすすめです。時間単位の中間テーブルから、下記のように派生して様々な中間テーブルが非常に少ない計算リソースで作成できます。計算リソースが少ないのでViewとして使っても良いと思います!
3. HLL sketchを用いた積集合(Insection)の異なり数集計
2.で紹介したように複数の集合のUnionの異なり数を計算できることが非常に嬉しい性質なんですが、おまけとして、2つの集合間の共通集合の異なり数もsketchを使うことで計算することが可能です。
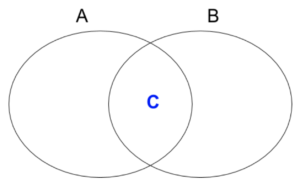
2つの集合AとBをベン図で表すと下図になり、知りたいのは集合AとBの両方に現れる集合Cに含まれる数です。
集合C(集合Aと集合Bの積集合) に含まれる数は次の式で計算できます。
![]()
つまり、Aの集合に含まれる数とBの集合に含まれる数を足して、AまたはBに含まれる和集合(Union)の数を引いてあげれば、目的の集合Cに含まれる数が計算できます。
どういうユースケースでこういうことができると嬉しいのでしょう。
例えば、ECサイトでの購買のトランザクションデータと、顧客管理マスタデータを紐付けて性別年代に分けてMAUを見たい場合があります。普通にやると1ヶ月分のトランザクションデータにuser_idをキーとして顧客情報を紐付けて、性別年代ごとにcount distinctをします。非常に計算コストが高い集計になります。
これもsketchを使えば圧倒的なパフォーマンスで近似値を得られます。
やってみましょう!
わかりやすく11月の男性(male)のユニークユーザ数を例として集計してみます。
count distinct
SELECT
users.sex,
count(distinct event_log.user_id)
FROM event_log LEFT JOIN users USING(user_id)
WHERE event_date between '2019-11-01' and '2019-11-30'
AND users.sex = 'male'
GROUP BY 1計算リソース:47.36 seconds, Data scanned: 93.46 GB
結果:15,206,051
WITH set_A AS (
SELECT
'A' AS set,
MERGE(CAST(hll_sketch AS HYPERLOGLOG)) AS hll_sketch
FROM day_level_aggregate
WHERE event_date between '2019-11-01' and '2019-11-30'
GROUP BY 1
),
set_B AS (
SELECT
'B' AS set,
APPROX_SET(user_id) AS hll_sketch
FROM users
WHERE sex='male'
GROUP BY 1
)
SELECT
CARDINALITY(MERGE(IF(set = 'A', hll_sketch))) + CARDINALITY(MERGE(IF(set = 'B', hll_sketch)))
- CARDINALITY(MERGE(hll_sketch)) as set_AB_uu
FROM (
SELECT * FROM set_A
UNION ALL
SELECT * FROM set_B
)計算リソース:Run time: 5.3 seconds, Data scanned: 1.83 GB
結果:15,028,505 (-1.12%)
期待通りの結果となりました。計算リソースの大半はusersテーブルから男性(male)のsketchを作るところに掛かっているので、こちらも事前にsketchを作っておくことでさらなるパフォーマンスの向上が見込めます。
まとめ
これまでユニークユーザ数を集計する際に、コスパが見合わないと色々と諦めていたところがHyperLogLogのsketchを使うことでほぼ解決します。もちろん、近似値という妥協はあるのですが、ほとんどのユースケースにおいて誤差1~2%ぐらいは許容の範囲内であると思います。失うごく小さな正確さに比べて圧倒的なコスパが得られ、それ故に実現可能になることがすごく増えるのでビッグデータを扱う上でHyperLogLog sketchは積極的に使う必須な技術だと思います。HyperLogLogを近似値が低コストで計算できるだけでしょ、使えそうなときに使うわと思っている人(私もその一人だった)は結構多いのではと思いますが、真価はsketchですので中間テーブルには積極的にHyperLogLog sketchを取り入れていくことをお勧めします!