

AI エージェント の本番運用における最大の課題、それは「信頼性」です。
大規模言語モデル(LLM)を活用した AI エージェント を「感覚頼み」ではなく、「科学的・継続的」に改善し、本番環境で運用し続けるにはどうすれば良いでしょうか?
この記事では、AI エージェントの品質保証という「地図のないフロンティア」に挑む、ある「評価基盤」の設計思想を公開します。その挑戦の中核から、AI の信頼性を高めるヒントをお届けします。
そのAI、本当に「賢い」ですか? AI 導入の現場で起きていること
「AI を導入してみたものの、期待したほど賢くない」「時々、もっともらしい嘘をつくため、安心して業務を任せられない」
いま、AI、特に大規模言語モデル( LLM )の活用に挑む多くの企業が、期待値と現実のギャップ、そして「本番利用への不安」という課題に直面しています。
なぜ、こんなことが起きてしまうのでしょうか?
その答えは、私たちの多くが陥りがちな「感覚頼りの開発」にあります。
最新の AI モデルを試し、新しい指示(プロンプト)を工夫して「前より良い感じになった」と判断する。これでは、まるで広大な海で羅針盤も海図も持たずに、船のエンジンを改良しているようなものです。目的地にたどり着くどころか、今どこにいるのかさえ分かりません。
この問題を OpenAI の共同創業者は次のような言葉で表現しました[1]。
“Evals are surprisingly often all you need” (驚くほど多くの場合、「評価」さえあればうまくいく)
― グレッグ・ブロックマン (OpenAI 共同創業者)
この言葉は、最新モデルや巧妙なプロンプトといった華やかな技術開発より、「地道な評価」こそが AI プロジェクトの成否を分けるという教訓を示しています。
開発者を悩ませる「評価の壁」:何をもって「正解」とするのか?
なぜこれほど重要な「評価」が、多くの現場で後回しにされてしまうのでしょうか。本当の課題は、誰もがその必要性を認識していながら、「具体的にどうやって AI を評価すれば良いのか分からない」という現実に直面し、有効な一手を打てずにいる現状にあります。
では、なぜ AI を評価することがそんなに難しいのでしょうか?
その答えは、評価の対象が根本的に変化したことにあります。従来のソフトウェアは「仕様通りに動くか」という明確な正解がありました。その後の機械学習( ML )も、「どれだけ統計的に正しいか」という指標で評価できました。
しかし、人間の言葉を扱う AI は次元が異なります。例えば「遅刻した時に怒られない言い訳を考えて」という問いに、唯一絶対の「正解」は存在するでしょうか?答えは無数にあり、文脈や相手との関係性によって最適解は変わります。「そもそも正解とは何か?を定義すること自体が難しい」これこそが、AI 評価の挑戦です。
特にビジネスの現場では、ChatGPT のような基盤モデルそのものよりも、それに社内データを組み合わせて特定の業務を支援させる「AI エージェント」の品質が重要になります。そこでこの記事では、この「AI エージェント」の評価に焦点を絞って話を進めます。
「地図のないフロンティア」を切り拓く:世界が注目する AI エージェントの評価
この「AI エージェントの評価」は、今まさに世界中の研究者が熱い視線を注ぐフロンティアです。
以下のグラフをご覧ください。これは、世界中の研究者が論文を共有するサイト「arXiv」に投稿された、「AI エージェントの評価」に関する論文数の推移を示したものです。
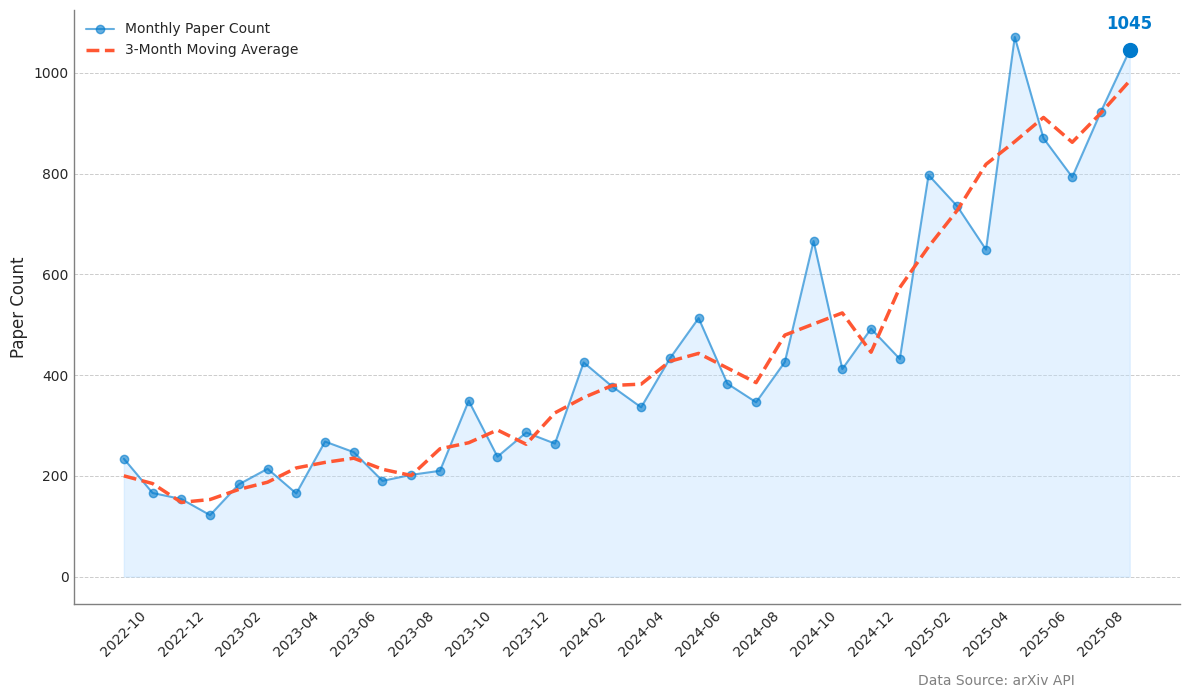
ChatGPT が登場した 2022 年末から徐々に増え始めた論文件数は、2025 年に入り、その伸びが急加速しています。このトレンドが意味するのは、AI エージェントが「試す」段階を終え、「実戦投入」の時代に入ったということです。学会にとどまらず、産総研が 2025 年 5 月に「生成 AI 品質マネジメントガイドライン」を公開するなど、国レベルの課題としても認識されています[2]。
このように世界中が模索を続けるフロンティアに、頼れる地図はありません。だからこそ我々は、まず自分たちの現在地と進むべき方角を知るための、信頼できる羅針盤を作り出すことから始めるのです。
Relevance Framework:Conata Data Agent 品質保証の羅針盤
ここからは、その羅針盤となる「Relevance Framework」について詳しくご紹介します。
この Relevance Framework は、我々が提供するデータ活用エージェント「Conata Data Agent(CDA)」の品質を継続的に高めていくための精度評価・改善の基盤として生まれました。CDAは、社内外の多様なデータを横断検索・要約し、お客様の業務課題解決や意思決定を支援する AI エージェントです。
先にお伝えしたように、AI エージェントの品質保証はまだ確立された方法が存在しない、成熟途上の分野です。そこで我々は、まず品質保証の「土台」となる基盤フレームワークを自社で構築し、その上で世の中の最新動向を迅速に取り込みながら独自の評価機能を育てていく方針を採りました。
AI エージェントの仕組み:評価すべき“パイプライン”を特定する
このフレームワークが何を評価するのかを明確にするため、まず評価対象である AI エージェントの仕組みを紐解いてみましょう。
AI がビジネスに役立つ回答をするためには、「一般的な知性」に加えて「企業固有の専門知識」が必要です。
現在の AI(基盤モデル)は、非常に高度な「一般的な知性」を持っており、実際、スタンフォード大学の「AI Index Report 2025」では一部領域ですでに専門家を凌駕すると報告されています[3]。しかし、企業が資産として保有する公開されていない専門知識は持ち合わせていません。
そこで AI エージェントが登場します。 AI エージェントは内部では精度向上のために様々な工夫が凝らされていますが、その本質的な役割を突き詰めると、次の 2 つの処理に集約されます:
- 検索(Retrieval):ユーザーの質問に答えるために必要な情報を、社内のデータベースや文書から探し出す
- 生成(Generation):集めた情報(コンテキスト)を AI に渡し、その知性を活用して、適切な回答を生成する
最終的な回答の「良さ」は、この検索と生成の両方にかかっています。そのため、最後の回答だけでなく、この一連の流れをもれなく評価する必要があるのです。
Relevance Framework の概要
では、このフレームワークがどのような全体像になっているのか、簡単にご紹介します。
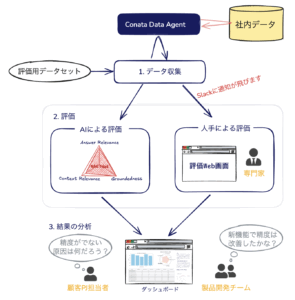
上の図に示されるように、フレームワークは 3 つのステップから構成されています:
- データ収集:評価データをここで一気に集めます。
- 評価:収集したデータを対象に「ゴールドスタンダードである人手評価」と「高速で網羅的な AI による評価」を行います。
- 結果の分析:数値データの視覚化や「改善が本物か」を判断する統計解析により、的確な次のアクションに繋げるための分析を行います。
以降、このステップに沿ってさらに詳細に説明を進めます。
ステップ 1. 評価用データセットとデータ収集
すべての評価の始まりとなるものが「評価用データセット」です。どれだけ評価手法を洗練させたとしても、評価用データセットの質が低ければ決して良い評価はできません。
質問の種類(事実の確認、要約、比較など)、データソースの種類(Google ドライブ、Slack 、データベースなど)、トピックスの種類(商談、社内規約、カスタマーサポートなど)、これらを組み合わせて多様な質問を作成します。各質問にカテゴリ情報を付与しておくことにより、精度が特に悪いカテゴリを識別するなど属性別分析が可能になります。
評価用データセットとは、素朴には「質問」と「期待する回答」のペアを集めたものですが、「回答」がなくても評価は可能です。現実的には、一定の数量を揃えるために、すべての質問に回答を揃えるのではなく、ポイントを絞って回答を作成し、質問については数量を増やすという戦略が有効です。
この評価用データセットを用いて、 AI エージェントから、回答やその回答を生成するために利用したコンテキストなどの内部情報を収集します。ここで収集したデータを、次に人間と AI が評価します。
ステップ 2. 評価
人手による評価:品質保証のゴールドスタンダード
冒頭で述べた「感覚頼りの開発」とは一線を画すのが、ガイドラインに基づいた専門家による系統的な人手評価です。これは、AI エージェントの品質を測る上でもっとも信頼性の高い「ゴールドスタンダード」と言えるでしょう。
しかし、この人手評価には避けて通れない 2 つの課題があります。
1 つは、「評価者間のばらつき」です。異なる評価者は同一の回答に対して異なる評価を与える可能性があり、日が異なれば同一の評価者であっても評価がブレる可能性があります。我々は、評価基準を明確化したルーブリック(評価基準表)を作成し、評価専門の担当者(専門家)を割り当てることにより評価の安定化を図っています。
もう 1 つが、評価に多大な時間とコストがかかる「スケーラビリティ」の問題です。これは AI 開発の迅速なイテレーションを妨げる、致命的なボトルネックとなります。レビュー専用 UI の整備や類似回答の評価を省略するトリアージ機能などにより効率化を進めていますが、完全な解決は困難です。
人手評価は品質の最終的な判断には不可欠です。しかし、そのスケーラビリティの限界を補い、日々の開発サイクルの中で迅速な評価を行うためには、機械的な自動化アプローチが必須になります。そこで我々は、次に説明する「AI による評価」の仕組みを導入しています。
AIによる評価:LLM as a Judge による高速フィードバック
人手評価のスケーラビリティという課題を乗り越え、迅速な開発サイクルを実現する鍵、それが「LLM as a Judge」です。LLM 自身の高度な言語理解能力を使って評価を行うため、人間による評価と高い相関を示すという報告もあります[4]。
この AI による評価について詳しく説明していきます。
正解データを用いない効率的な評価:RAG トライアド
多くの実用シーンで求められる、正解の定義がない場合の評価では、2023 年に発表され、瞬く間に業界標準となった「RAG トライアド」という 3 つの指標を評価の柱として採用しています。
- Answer Relevance(回答の関連性): 「ちゃんと質問に答えているか?」
- Groundedness(忠実性): 「参考情報に基づいており、ウソをついていないか?」
- Context Relevance(文脈の関連性): 「参考にした資料は的確か?」
RAG トライアドの素晴らしい点は、AI の回答を多角的に評価できることにあります。AI の回答は、これら 3 つの指標をすべてクリアして初めて「本当に良い回答」と認められます。 たとえば、「質問には答えている(Answer Relevance)」ように見えても、「根拠がない嘘(Groundedness)」であれば失格です。また、「嘘はついていない(Groundedness)」としても、「的外れな情報を参照(Context Relevance)」していれば、やはり信頼できません。 このように、RAG トライアドは AI 回答の品質を担保する、強力な指標なのです。
一方、指標は広く採用されていますが、その指標をどう計測するかという実装においては各社ばらつきがあり、独自の工夫を入れ込むポイントになっています。我々は、たとえば次のような工夫を加えています:
- 解釈可能性の重視: Ragas 論文で提案されているような埋め込み表現の類似度によるスコアリング [5]は、結果の解釈が困難です。我々は LLM に直接スコアをつけさせ、同時にそのスコアをつけた理由を出力させることにより、評価の妥当性を人間が検証できるようにしています。
- 指標の解像度向上: Context Relevance を、「網羅性(十分な情報があるか)」と「精度(必要な情報だけあるか)」という 2 つの指標に分解しています。これにより、「情報不足」なのか「ノイズ過多」なのか、原因をより解像度高く特定できます。
しかし、RAG トライアドには、ビジネス上の深刻なリスクを見逃す限界があります。それが「Version Drift」[6]、すなわち AI が古い情報を参照する問題です。
実際の訴訟事例[7]にもあるように、AI が古い規定に「忠実な」回答を返した場合、RAG トライアドは「情報源に忠実である」と高く評価してしまいます。この手法は「情報源が最新で正しいか」までは判断できないのです。
正解データを用いた厳密なファクトチェック
この「Version Drift」のように事実の正確性が問われる問題に対処するには正解データが必要になります。AI に限らず、人間でも「あれ?このドキュメントが最新版じゃなかったの?」ということがしばしばあります。
質問に対する「模範回答」を正解として定義する方法に加えて、我々は nugget(ナゲット)というアプローチに注目しています。 これは 2003 年の TREC で導入された歴史ある手法ですが [8]、最新の「TREC 2024 RAG Track」でも、LLM による自動評価と組み合わせて採用されたことで、再び脚光を浴びています [9]。 nugget は、一つの完璧な模範回答を用意する代わりに、「回答が含むべき重要事実のリスト」を定義します。
例えば「アインシュタインはどんな人?」という例を考えてみましょう。 模範回答では「相対性理論を提唱した物理学者です」という一つの文章になりがちですが、 ナゲットならば「相対性理論」「ノーベル物理学賞」「E=mc²」といった重要事実のリストを使って柔軟に評価できるのです。
「正解データ」の定義には手間がかかりますが、これも AI を使って効率化できます。実際、TREC ではナゲットを自動的に抽出するツールを使い、その実装は公開されています[10]。
ステップ 3. 結果の分析
まだ試作段階ですが、フライウィールでは結果を視覚的に確認できるダッシュボードを提供しています。左側が 1 つの評価結果を分析するためのビューであり、右側が 2 つの評価結果を比較するためのビューになります。結果の比較は、ある変更による精度改善の効果が期待通りに出ているかどうかを確認するために用います。
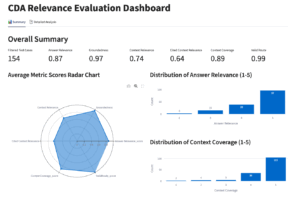
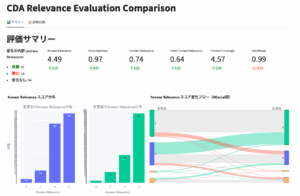
評価の最終目的は、スコアを出すことではなく、次なる改善のための洞察を得ることです。数字の羅列だけでは見えにくい傾向や課題を、ダッシュボードは視覚的に明らかにします。
統計的有意差の検証:改善は本物か、偶然か?
ダッシュボードでスコアの向上が確認できたとしても、それを即座に「改善」と判断するのは早計です。なぜなら、そこには次の 2 種類のばらつきが常に存在するからです:
- LLM の回答自体のばらつき
LLM は本質的に確率的な振る舞いをします。同じ入力に対しても出力は完全に同一にならず、プロンプトの僅かな違いにも敏感に反応するため、パフォーマンスには常にばらつきが生じます。 - 評価のばらつき
自然言語の評価は主観性を伴います。評価者間はもちろん、同じ評価者内でも評価基準には揺らぎが発生します。これは LLM を評価者として利用する場合でも同様です。
このばらつきを踏まえて結果を解釈しなければ、本当に精度が上がったのか、あるいはたまたま結果のばらつきでよく見えたのかその区別がつきません。
Relevance Framework は、こうした評価の安定性や有意差を検証するための統計解析の機能も備えています。これにより、「その改善は本物か、それとも単なる偶然か」を科学的に判断することが可能になります。
評価のその先へ:AI による自律改善と信頼を設計するガバナンス
評価基盤構築の試みは始まったばかりであり、関連技術も日々アップデートされています。やるべきこと、やりたいことがまだまだたくさんあります。
私たちの取り組みの最終目標は、「評価結果から改善アクションが生まれ、そのアクションの結果を再度評価して改善効果を確認する」というサイクルを、人間が介在するコストを最小化しながら高速で回すことです。
さらに長期の視点で見ると、現在は人間が評価の結果から課題を分析し改善アクションを決定していますが、将来的には、評価の結果から課題を分析し、仮説を立て、改善アクションを実施するところまで AI に担当させる「 AI による AI の自動改善」のフェーズに進むことを視野に入れています。
ではその AI を評価する AI の正しさはどのように担保するのか?
ここから先は評価ではなく AI ガバナンスの話になると考えています。AI が人間の期待通りに動くことを保証する仕組み、これをしっかりと考えていくことがこれから先は重要な課題になるはずです。
フライウィールは、この AI エージェントの「信頼性」という最先端の技術的課題に、真正面から取り組んでいます。Relevance Framework はその挑戦の中核です。最先端の研究成果を、本番環境のデータで検証し、実用的なソリューションへと昇華させることに熱意を持つ開発者の皆さんとの、新たなチャレンジを楽しみにしています。
◼︎エンジニアリング部門の採用情報はこちら
References
- [1] Greg Brockman on X ↩
- [2] 生成 AI 品質マネジメントガイドライン ↩
- [3] Artificial Intelligence Index Report 2025 | Stanford HAI ↩
- [4] Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena ↩
- [5] Ragas: Automated Evaluation of Retrieval Augmented Generation ↩
- [6] Enterprise AI Version Drift: The Hidden Risk & How to Fix It – Ajith’s AI Pulse ↩
- [7] Airline held liable for its chatbot giving passenger bad advice – what this means for travellers ↩
- [8] Overview of the TREC 2003 Question Answering Track ↩
- [9] Initial Nugget Evaluation Results for the TREC 2024 RAG Track with the AutoNuggetizer Framework ↩
- [10] castorini/nuggetizer ↩
