データインフラ
AI-Ready データの 6 条件を基準にしたデータインフラ
Conata® のデータインフラは、「AI が使えるかどうか」を判断基準として設計されています。
AI が理解し、判断し、活用できる状態=
AI-Ready データを最短距離で実現します。
AI-Ready データを定義する、
6つの条件
Conata® は、以下の 6 条件を
すべて満たすデータ環境を
最短で、運用可能な形で構築します。
- 分かりやすい構造
- 適切な意味づけ
- 統一された管理
- 継続的な改善
- 高い品質
- スケーラビリティ
あらゆるクラウドシステム、サーバー、
ファイルタイプ、データ構造に対応可能です。
分かりやすい構造
ドメインモデルに基づき、
文書・データを AI が理解しやすい
構造に整理。
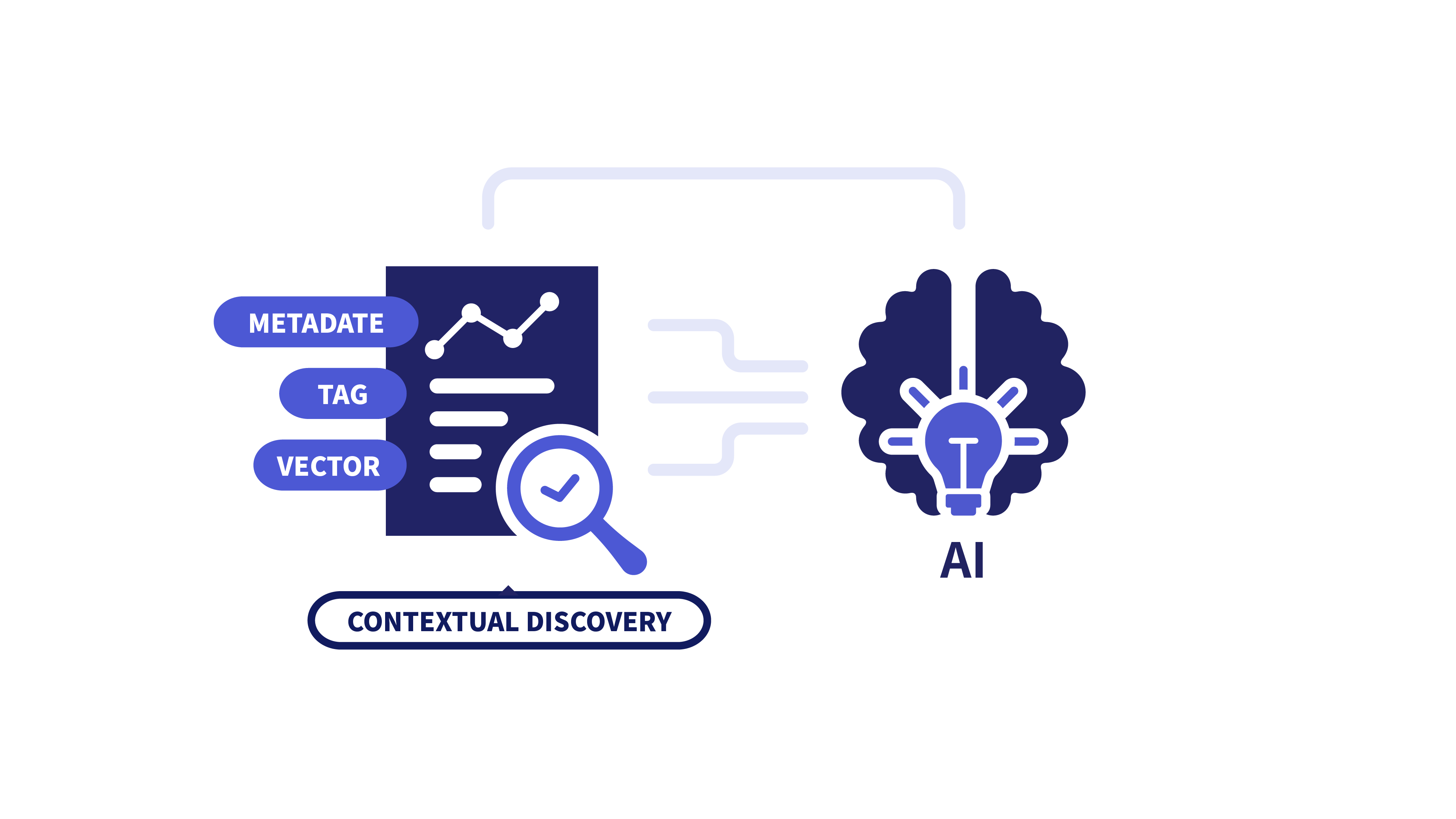
適切な意味づけ
メタデータ・タグ・ベクトル化により、
非構造化データも意味検索可能に。
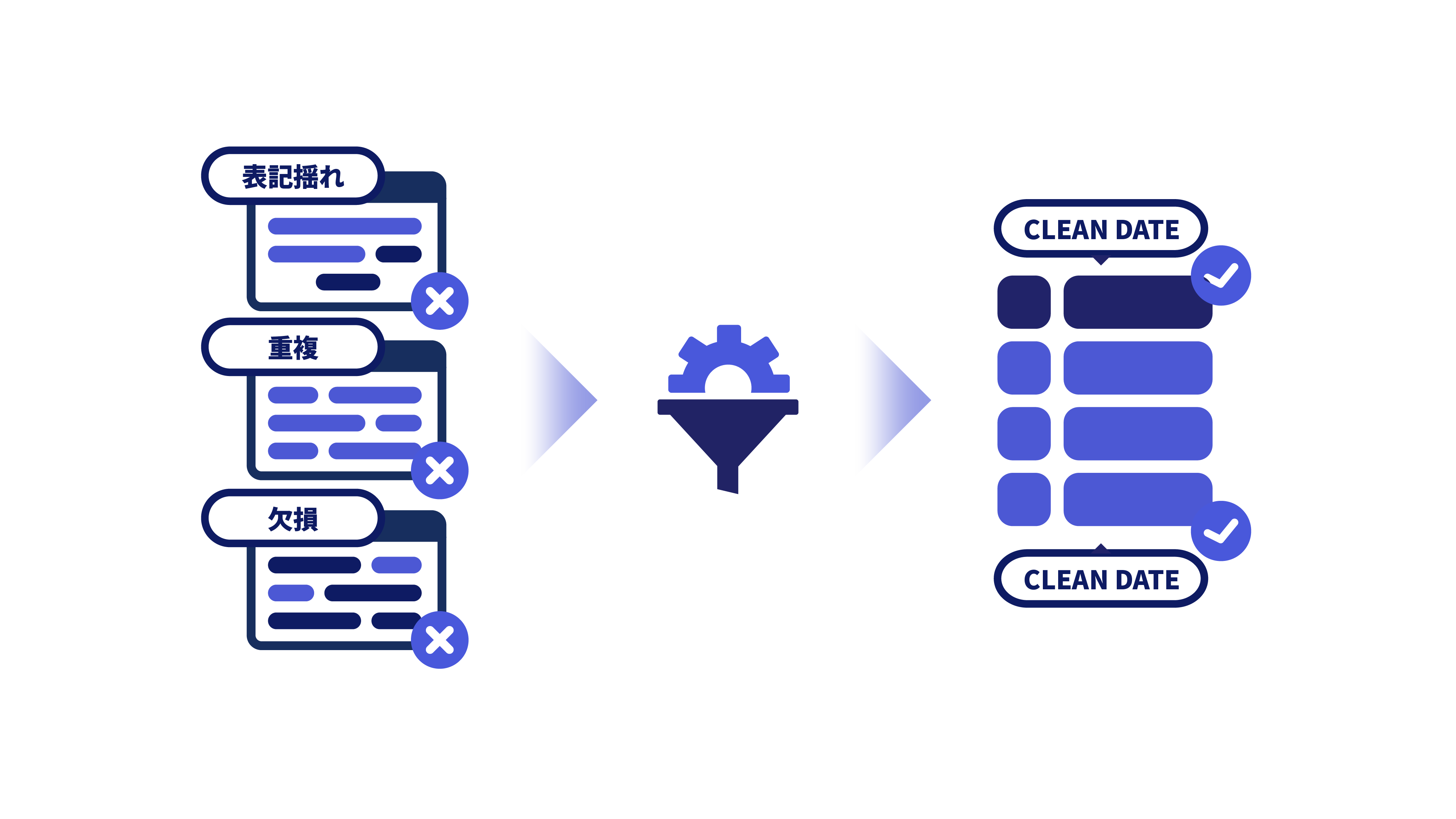
高い品質
表記揺れ・重複・欠損を補正し、
AI の誤学習を防止。
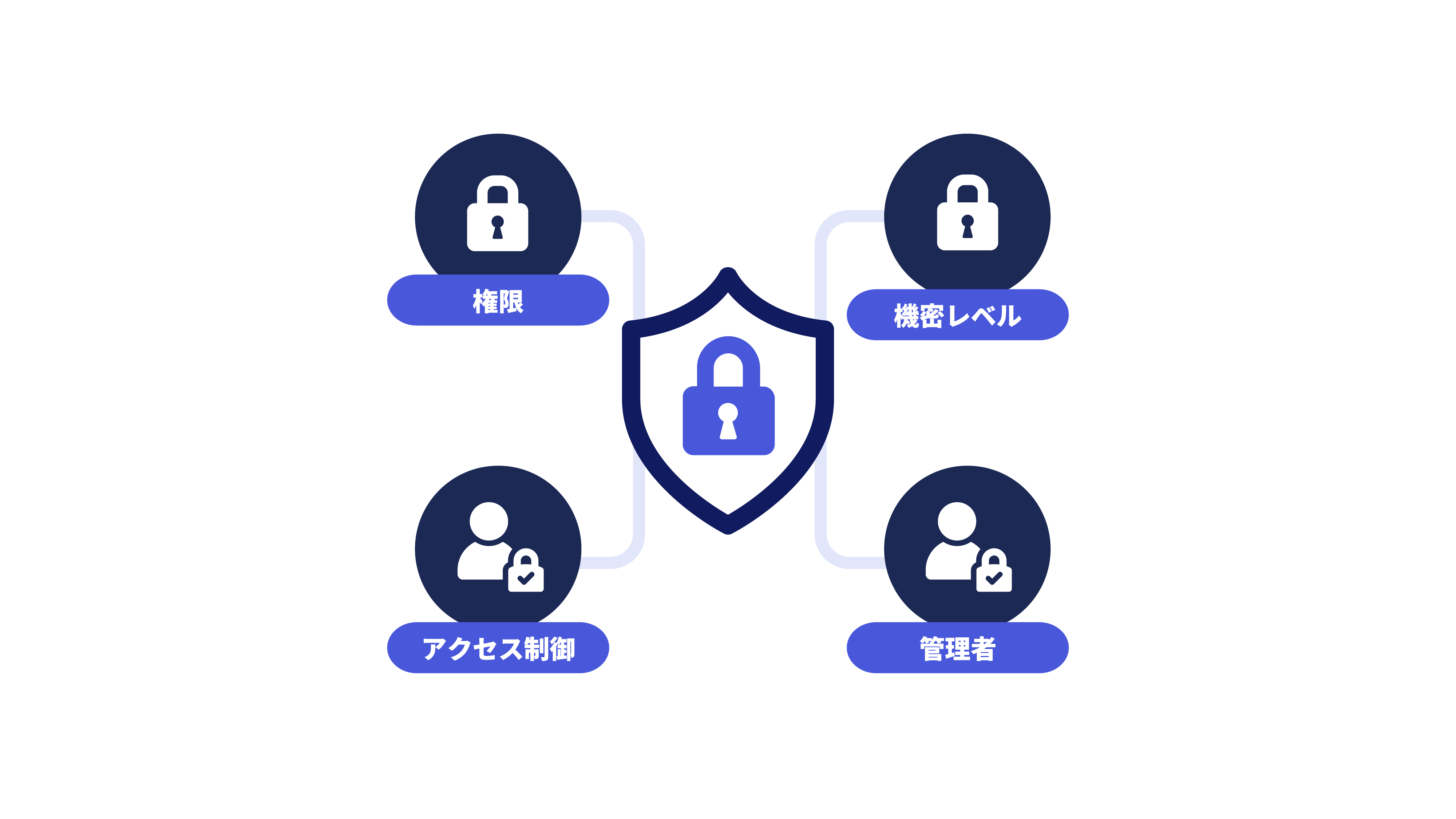
統一された管理
権限・機密レベル・アクセス制御を
一元管理し、安全な AI 運用を実現。
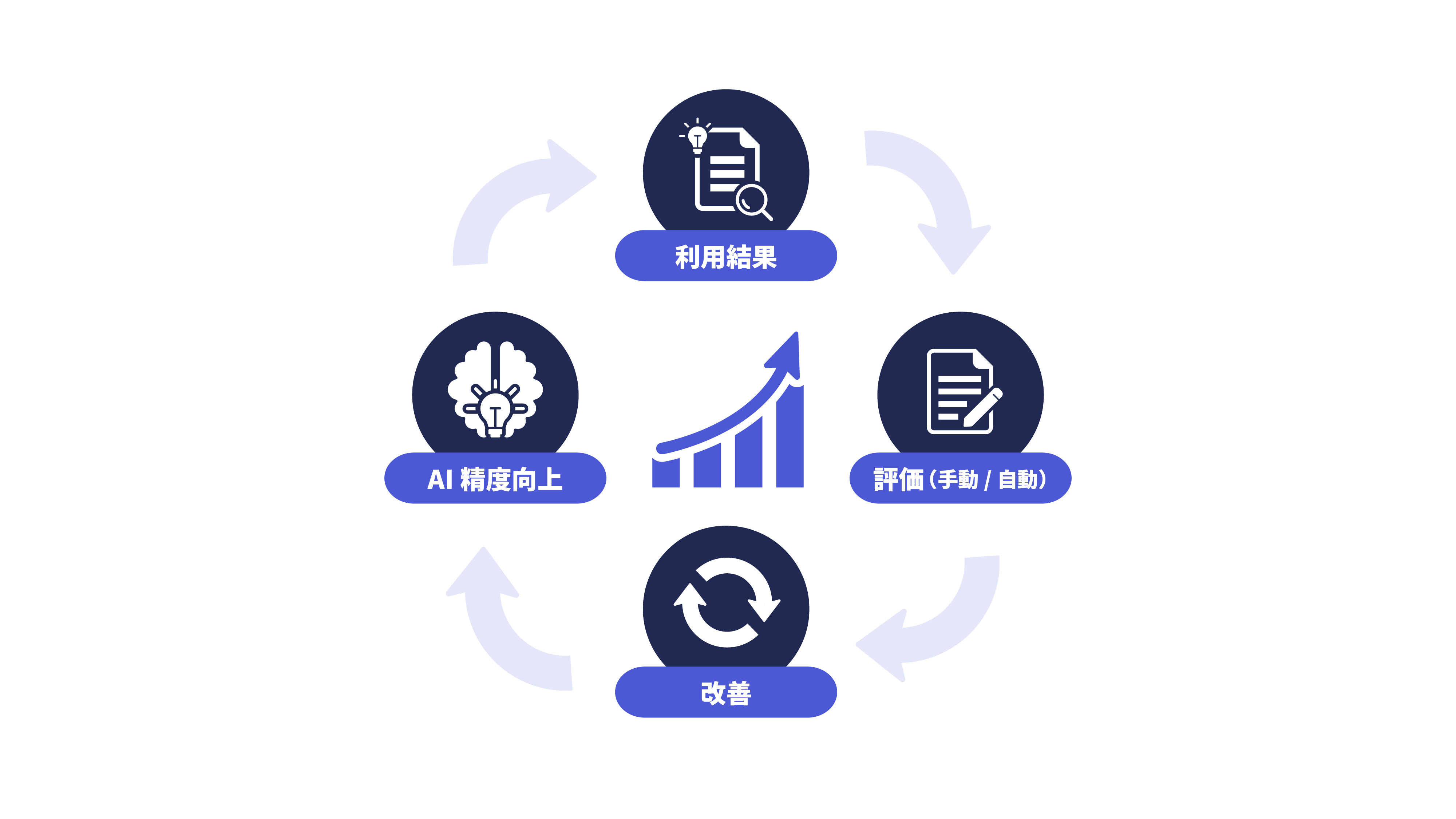
継続的な改善
利用ログを活用し、AI 精度を
運用しながら継続的に向上。
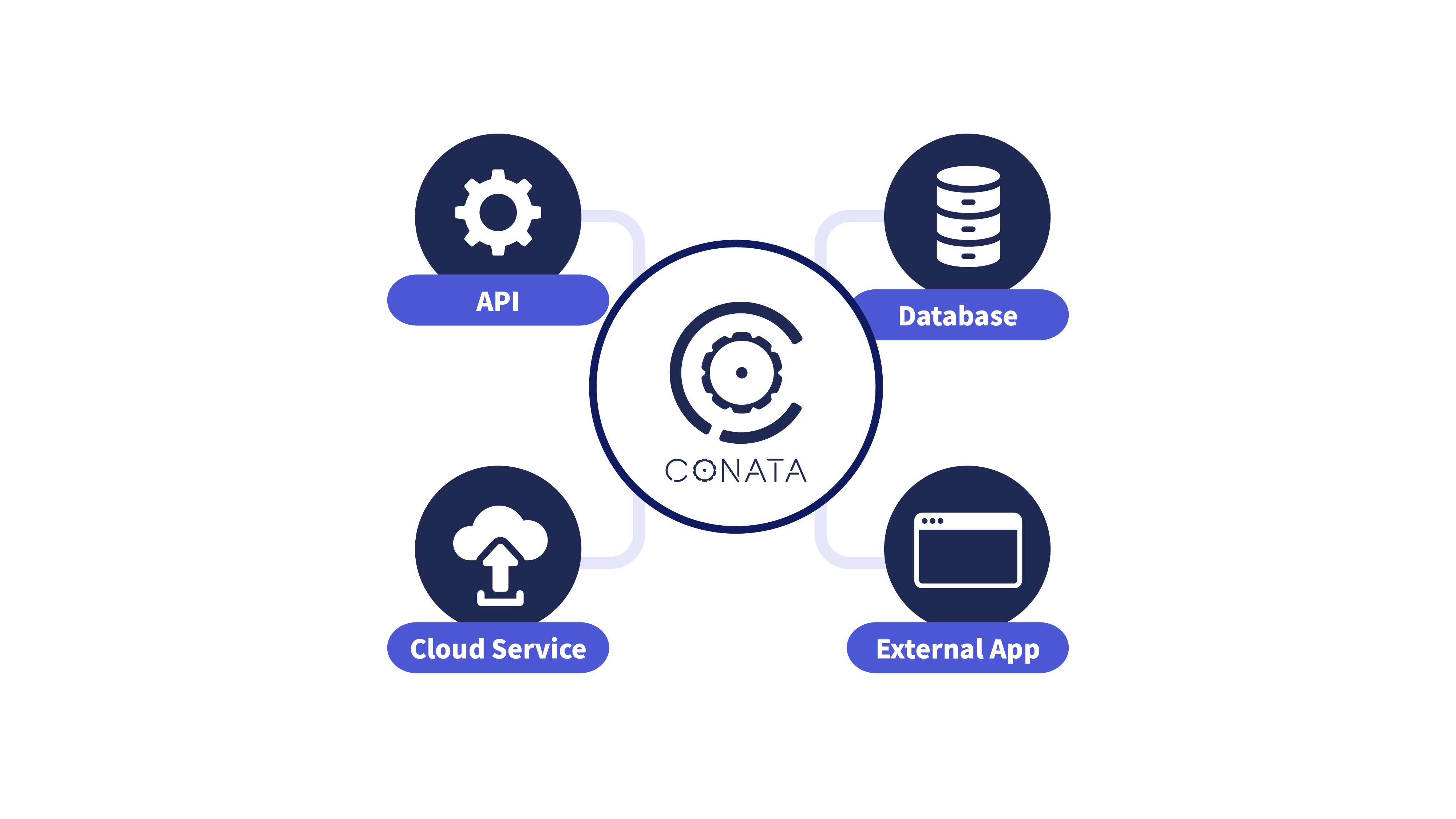
スケーラビリティ
API / MCP を通じて外部システムと接続し、
ユースケースを柔軟に拡張。
Conata® のデータインフラは、
それ単体で完結するものではありません。
AI-Ready なデータを前提に、
検索・分析・予測・業務支援といった
データアプリへ
スムーズにつながることを
前提に設計された基盤です。