

前回ではログを解析するための前処理の重要性について触れました。今回はFLYWHEELが提供するCDPの基礎にもなっているセッション化の意義について紹介したいと思います。
セッション化
この記事ではセッション化を「ユーザーの行動をまとめたログ」と定義します 。たとえば加工されていないログは以下のように、個々のイベントがユーザーに関係なく時間軸で並んでいます。
- 10:00 – 匿名ユーザー A が商品 X を閲覧
- 10:01 – ユーザー B が商品を検索
- 10:02 – 匿名ユーザー A が、ユーザー C としてログイン
- 10:03 – ユーザー B が商品 X を閲覧
- 10:04 – ユーザー C が商品 Y を購入
これをユーザーごとにまとめると以下のようになります。
- ユーザーC(=匿名ユーザーA)
- 10:00 – 匿名ユーザー A が商品 X を閲覧
- 10:02 – 匿名ユーザー A が、ユーザー C としてログイン
- 10:04 – ユーザー C が商品 Y を購入
- ユーザーB
- 10:01 – ユーザー B が商品を検索
- 10:03 – ユーザー B が商品 X を閲覧
なぜ単なる時系列のイベントではなく、ユーザー毎の行動を流れで追う必要があるのでしょうか? たとえば商品のレコメンドを機械学習で最適化することを考えます。ある商品をおすすめしたときのCTRを予測するための特徴量としては、アイテムの属性情報や、ユーザーの状況や属性情報、レコメンドの表示された枠やページの属性情報が考えられます。そのような特徴量に加えて、実際にユーザーにクリックされたかどうかをラベルとしてトレーニングデータが作られます。それらの情報はさまざまなログに別々のイベントとして記録されているため、ユーザー毎にイベントを集め、各クリックがどのレコメンドから起きたものなのか関係を突き止める必要があります。このように、機械学習のトレーニングデータを作る際には、たいてい入力の特徴量と予測したい値であるラベルが別々のイベントとして記録されているため、ユーザー軸で複数のログをまとめる必要があります。
また単なるイベントの列としてのログを使ってユーザーの行動を流れで追うことは困難が伴います。たとえば「商品 X の詳細画面を確認したあとよく買われる商品」を知りたいときは、
- アクセス履歴のログと購入履歴のログをユーザーで結合
- 商品 X の詳細画面を見たユーザーをフィルター
- 商品 X を閲覧してから30分以内に買った商品を購入履歴から集計
といった複雑な解析をしなければなりません。さらには上の例にもあるように商品を購入する段階になって初めてログインするユーザーなどは、閲覧時と購入時のイベントに記録されたユーザーIDが異なるため、ログインの記録を使って匿名IDとユーザーIDの紐付ける必要があります。ECサイトでは購入フローに入って初めてログインするユーザーも少なくないため、このようなケースを見逃すとカバレッジが大きく下がります。
共通基盤を使って複雑性を減らす
もちろん各プロダクトやチームが、複数のログを組み合わせ分析することで、自分たちによって必要なユーザの行動の流れを作ることは不可能ではありません。しかし「複数のログを組み合わせる」という一見簡単な作業が、以下のような理由で実は単純ではないことは既存の論文で指摘されています。1
- ログの所在
- ログを見つけること、つまりどんな種類のログがどこに保存されており、どんなフォーマットで書かれているのか発見することは分析の初期段階において大きな課題となる。
- ログのフォーマット
- 値の型:たとえば時刻の値ひとつとっても、その型は整数・浮動小数点数・文字列と複数の可能性がある。数字で表された時刻は、単位を間違え秒とミリ秒を比較するようなバグを埋め込みやすく、文字列の場合はフォーマットや、タイムゾーンを含むか否かなどの問題がある。
- フィールドの名前の一貫性:たとえばユーザーIDを表すフィールドは各ログによって異なっていることが多く、どこに保存されているのか見つけるのは困難 (id, user_id, owner_user_id, author_id, user.id 等々) 。
- 用語の定義の不一致:1つのフィールドが複数の意味を持っている場合、正しく扱うことは困難である。たとえば category というフィールドが、購入履歴の場合はアイテムのカテゴリー、検索ログの場合はカテゴリー検索条件、購入履歴の場合はトランザクションの種類を扱うといったように別々の目的で利用されている場合、おなじ category でもログの種類によって扱いを変えなければならない。
- ユーザーの識別
- 「ユーザーで結合」する処理はいつも簡単にできるとは限らない。ユーザーの識別子はたいてい、クッキーやアプリで生成したID、登録ユーザーIDなどさまざまな種類が存在し、ログによって異なるIDを記録していたり、そもそも別のIDを取れなかったりする。
- 指標の標準化
- たとえば DAU (Daily Active User) を各機能ごとに定義すると、それぞれのDAUは異なった意味を持っているため、比較するのが不可能になる。
- 新しいログの利用
- 新しいログを追加した時、活用するには、他のログと結合する処理をそれぞれのアプリケーションで書かなければならない。スキーマがドキュメント化されていない場合、ログの意味を解釈するためには、サーバーコードおよびETL処理を読んで解釈する必要がある。
- アクセス権限の最小化
一部の問題は、データウェアハウス が一貫性をもって設計され、ETLが適切に行われていれることで解決しますが、それでも N 個のログと M 個アプリケーションがあるとき、 こうした複雑性は N x M の組み合わせ分だけ発生しえます。
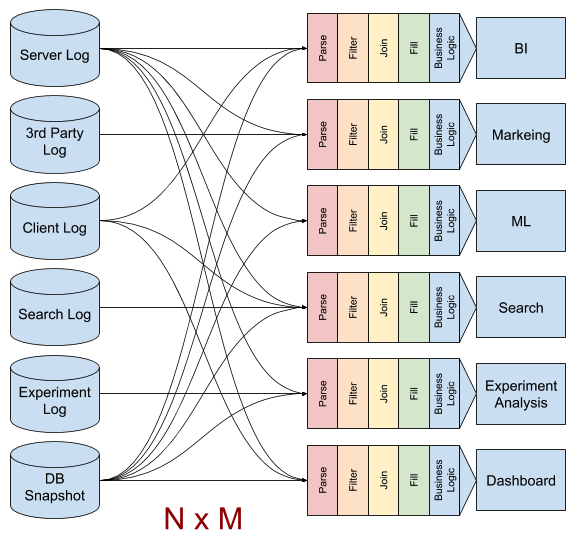
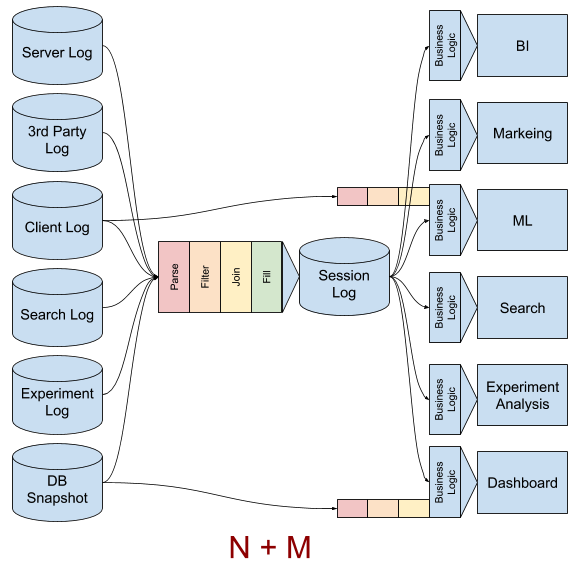
ログを収集し、解釈し、結合するステップをセッションログのパイプラインに集約し、各アプリケーションがセッションログを使うことで複雑性を減らすことができます。セッションログパイプラインは N 個のログに対処し、1つのセッションログを出力し、M 個のアプリケーションはセッションログをメインとして使うことで、全体の労力を N + M に抑える事ができます。
セッションログのスキーマ
セッションがデータベースに蓄えられているとき、どのようなスキーマを持つべきでしょうか? BigQuery や PostgreSQL、JSON など繰り返し (Array) を扱えるストレージでは、1つのエントリーが一つのセッションに対応し、イベントのリストを持つようにスキーマを定義できます。 データベースが繰り返しをサポートしていない場合、もしくはフラットなスキーマにしたい場合は、セッションごとのユニークなID(session_id)を各ログレコードに書き込むことで、セッションを表現できます。セッションデータをクエリすることは session_id で GROUP BY することになるため、そういったクエリが最適化されるようにデータをストアすることが必要です。
セッションのアプリケーション
セッションログはさまざまなアプリケーションで利用可能です。
- 統一的なメトリック
- セッションログを使うことで、統一的なメトリック(たとえば DAU)をプロダクトレベルで定義し、さらにプラットフォームや機能毎に掘り下げることができるようになる。
- 機械学習
- 機械学習のトレーニングデータを作る際、入力の特徴量を作るためのユーザーのプロファイルとイベント(検索結果を表示する、関連商品をおすすめする)および、それに対するユーザーのリアクション(クリックされた商品、購入まで結びついた商品)を組み合わせる必要があり、セッションデータがあれば効率的に行える。
- ファネル分析
- 高度なメトリック
- 検索においては、CTRはわかりやすいメトリックだが、クリックして1秒後にすぐに検索画面に戻ったとしたら、それは良い結果だと言えない。ユーザーが本当に必要な情報を見つけられたのであれば、ユーザーがクリックしたあと長い時間をサイトで過ごす、もしくは戻ってこないはずである。6 セッションログならば、クリックなどの個々の行動だけでなく、滞在時間などのユーザーの行動の流れに基づいた複雑な Metrics を定義できる。
- 検索
セッションログとアクセスコントロール
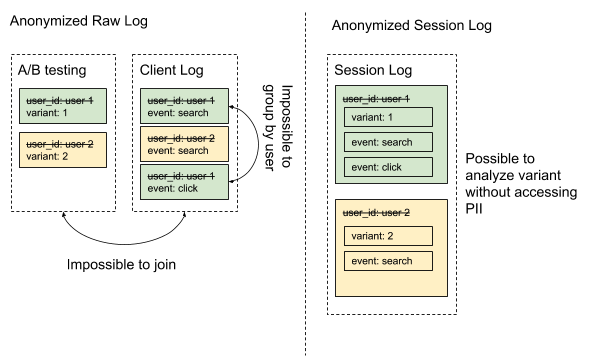
すでに情報のアクセス権限を制限する重要性について述べましたが、ユーザーIDのような一見安全そうに見えるデータも実はセンシティブな情報です。もし悪意のある社員が友人の行動を調べようと考えた時、もし友人のIDを知っていれば、簡単にさまざまなログから情報を集めることができます。しかしログが匿名化されユーザーIDを含まないと、一人のユーザーの行動を追いかけたり、複数のログやデータベースと結合することができません。
しかし、セッションログでは、一人ひとりのユーザーの行動がセッションとしてまとまっていることで、匿名化され、ユーザーIDにアクセスすることなく安全な状態のまま、上記のような解析が可能になります。
まとめ
セッション化されたログは各アプリケーションが複数のログを理解し組み合わせる労力を減らし、ユーザーを特定し、各ユーザーごとにイベントをまとめるという、計算コストの掛かる処理の共通化します。その結果、ユーザーの行動の流れの中で分析することを容易にし、元のログへのアクセスや、ユーザーIDなどの個人情報へのアクセスすることなく安全に解析することが可能になります。
Notes
- The Unified Logging Infrastructure for Data Analytics at Twitter https://arxiv.org/abs/1208.4171 ↩
- Twitter alerts users: Please change your passwords, we’ve seen them
https://arstechnica.com/information-technology/2018/05/twitter-advises-users-to-reset-passwords-after-bug-posts-passwords-to-internal-log/ ↩ - Google Confirms That It Fired Engineer For Breaking Internal Privacy Policies | TechCrunch – https://techcrunch.com/2010/09/14/google-engineer-spying-fired/ ↩
- What Is Product Excellence by Google Product Manager https://www.slideshare.net/productschool/what-is-product-excellence-by-google-product-manager ↩
- What To Do If Your Product Isn’t Growing – Initialized Capital – Medium – https://medium.com/initialized-capital/what-to-do-if-your-product-isnt-growing-7eb9d158fc ↩
- How a Search Engine May Measure the Quality of Its Search Results – http://www.seobythesea.com/2011/09/how-a-search-engine-may-measure-the-quality-of-its-search-results/ ↩
- Learning dense models of query similarity from user click logs – https://dl.acm.org/citation.cfm?id=1858070 ↩
- Relevant term suggestion in interactive Web search based on contextual information in query session logs (2003) http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.86.9419 ↩
- Clustering Query Refinements by User Intent – Google AI – https://ai.google/research/pubs/pub36242 ↩