

プロダクトマネージャーのKSKです。前々回、前回に引き続き、社内のSlackで使われた絵文字を調査する個人プロジェクトについて書いていきたいと思います。
(注意:今回の投稿には統計手法を用いた解釈や分析のためのコードを書いていますが、社内共有用の情報であり必ずしもベストな手法やコードになってないことを予めご承知ください。弊社エンジニアの見解やコードが見たい場合は他のブログ記事をお読みください。なお、本記事においてのご意見・ご感想は大歓迎なので、弊社ホームページの「お問い合わせ」から連絡いただき、そのまま弊社に直接ダメ出し、ついでに遊びに来てください。)
今回は(ついに!)整形されたデータを実際に分析して、社内で使われている絵文字やチャンネルによる違い、さらには自分の特徴的な絵文字の抽出までやってみたいと思います。
Slackから落としてきた情報の構成およびデータをどのように整形したいかについては前々回の投稿を、実際にRubyのコードを書いてテキスト形式で出力した方法については前回の投稿を参照してください。
さて、日常業務でExcelのピボットテーブルは愛用していますが、ちょっと複雑な操作は難しいですし、何よりこれはテックブログです。何の言語を使うか・・・あまり複雑なコードを書こうとして完成できずにブログが書けなくなって挫折したくないので、できるだけ楽にやりたいです。
ふと、浮かびました。
「数値計算や統計分析ならPythonでしょ!」
もはや前回のブログに無理やりあわせている感が強いですが、その言葉がよぎったので誰がなんと言おうと Python で書くことにします(今回は実際に数値計算や統計分析をするはずです!)。Jupyter notebook を使って一行一行動作を確かめながらやるのがオススメです。Python 自体や Jupyter などのツール、NumPy や Pandas などのライブラリのインストールについての説明はここでは省略します。
まずはシンプルに、社内で一番使われている絵文字は何か調べてみましょう。
今回はランキング形式でTOP10を出すことにします。
最初におまじないを書きます。(ライブラリを呼び出します)
import scipy as sp
import scipy.stats
import pandas as pd
from IPython.display import display前回作成したファイルを読み込みます。下記では “emoji.txt” として前回作成したファイルをTSV形式で保存し、本コードと同じ場所に保存していることを想定して書いています。
emoji_df = pd.read_table("./emoji.txt")たったのこれだけで準備が完了しました。Jupyter notebook を使っているとテーブルの中身を確認することも楽チンです。
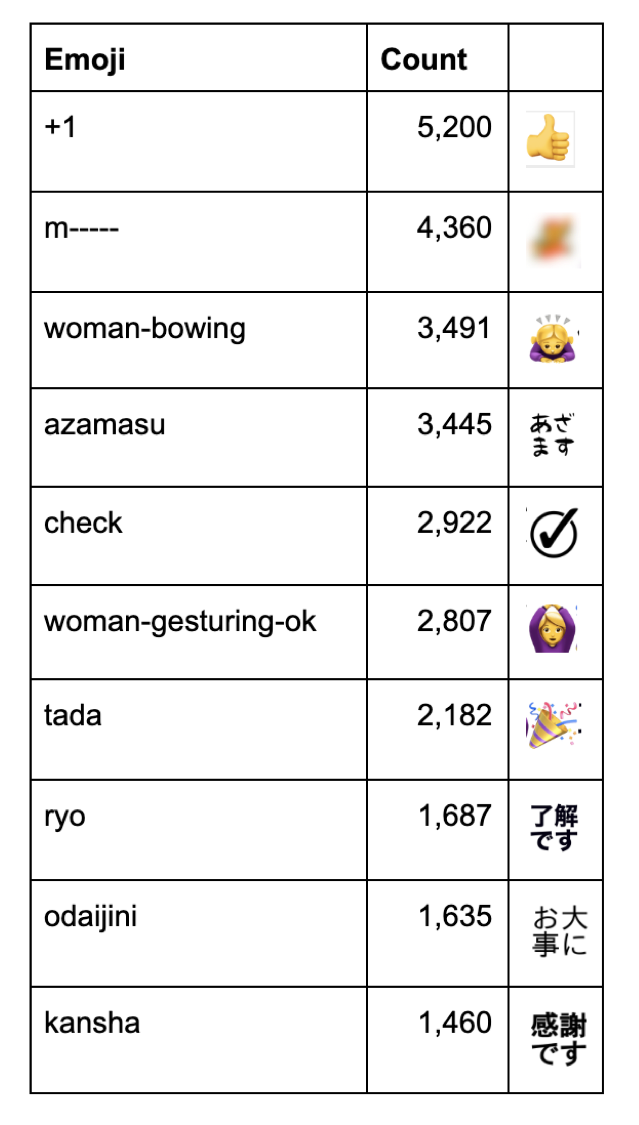
さて、社内で一番使われている絵文字TOP10の出し方ですが、「”Emoji” 欄に書かれた絵文字ごとに集計して回数を算出し、回数が多い順に並べ替えて頭から10件を抽出する」という作業が必要です。これがなんとたったの1行のコードで出せるのです!自分でもすぐに出すことが出来ました!慣れればExcelのピボットテーブルよりも早くできそうな予感がします。
emoji_df.groupby('Emoji').size().sort_values(ascending=False).head(10)各作業は以下のように対応しています。わかりやすい。
- 「”Emoji” 欄に書かれた絵文字ごとに集計」→ groupby(‘Emoji’)
- 「回数を算出し」 → size()
- 「回数が多い順に並べ替えて」 → sort_values(ascending=False)
- 「頭から10件を抽出する」 → head(10)
出力結果は以下のようになっています。わかりやすさのために画像もつけています。
(一部著作権等の関係で曖昧にしている部分がありますがご了承ください)
全体の合計だけでなく、様々な切り口で調べることができます。
random チャンネル内で使われている絵文字 TOP10
emoji_df[emoji_df.Channel=='random'].groupby('Emoji').size()\
.sort_values(ascending=False).head(10)ユーザー KSK が使った絵文字 TOP10
emoji_df[emoji_df.React=='KSK'].groupby('Emoji').size()\
.sort_values(ascending=False).head(10)試しに、自分(KSK)と、「とあるエンジニアがWFHしたときのとっても詳細な1日の流れ」を書いていた猫好きエンジニア kktn、今回テックブログに初挑戦する人事採用担当 Maikoで試してみたら、このようになりました。
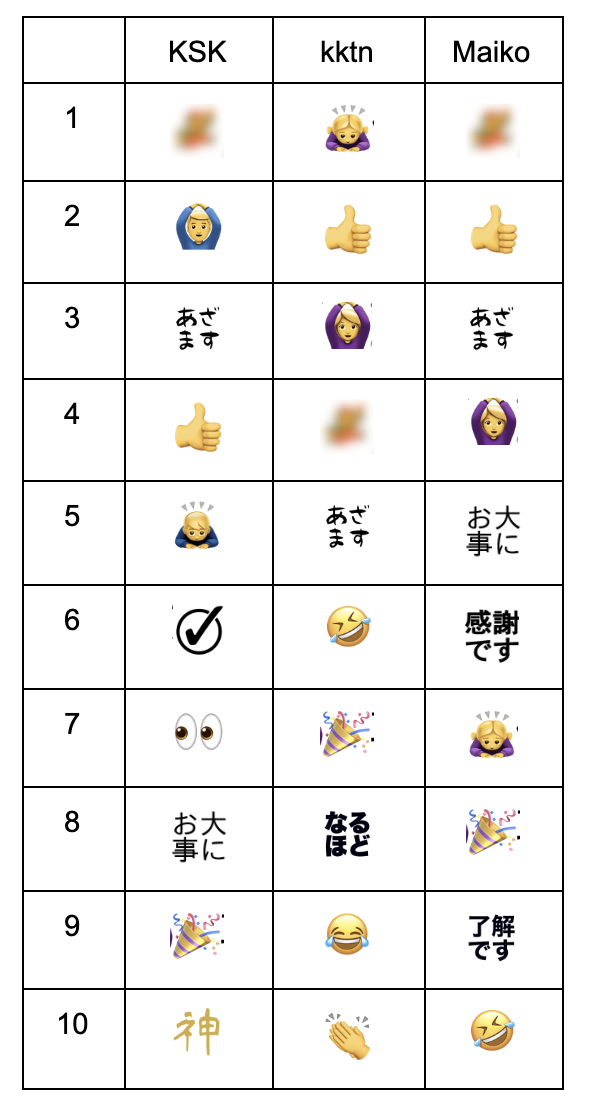
これだけでもだいぶ面白いですね。全員に出てくる絵文字もあれば、一人だけにしか表れない絵文字もあります。また、この3人に関わらず絵文字の性別を使い分けているのも改めて見ると面白いなぁと思いました。
ただ一方で、Maikoの絵文字TOP10は全体の絵文字TOP10と実に9個も被っています。単純に回数だけで順位付けをすると、人によってはその人の特徴をあまり反映できていないことになります。これは違う!自分が求めていたのは、その絵文字セットを見ただけでその人だとわかるような「〇〇らしい絵文字TOP10」なんだ!
というわけで、ちょっと調べてみました。
どうやら特定の絵文字において、対象のユーザーがその絵文字を使う頻度が、平均的なユーザーがその絵文字を使う頻度よりも大きいと言えるかは、適合度のカイ二乗検定を用いて評価することができそうです。
この場合、
帰無仮説 H0:
対象のユーザーがその絵文字を使う頻度が、平均的なユーザーがその絵文字を使う頻度と同程度である
対立仮説 H1:
対象のユーザーがその絵文字を使う頻度と、平均的なユーザーがその絵文字を使う頻度は異なる
となり、対象のユーザーがその絵文字を使う頻度が平均的なユーザーがその絵文字を使う頻度より大きく、かつ帰無仮説 H0 を棄却する理由が強い(≒ カイ二乗値が大きい)ほど、「そのユーザーらしい絵文字である」と言える可能性が強そうです。
ということで、実装してみましょう。
Python の NumPy ライブラリを使うと、カイ二乗値を出す関数は下記の通り簡単に書くことができました。
def calc_chi2(x, all_personal, all_others):
return sp.stats.chi2_contingency(
[[x.personal, x.others],
[all_personal, all_others]])[0] # returning chi2_value次に「何らかの方法で絞ったとき(ここでは対象のユーザー)の個々の絵文字の回数と全体(ここでは全ユーザー)の絵文字の回数からなるテーブル」を渡すと、すべての絵文字に対してカイ二乗値を算出し、平均より利用頻度が高い絵文字のうち、カイ二乗値が高い(=そのユーザーに特徴的である可能性が高い)絵文字TOP10を返す関数を書きます。
def get_top_emojis(tmp_df):
tmp_df['others'] = tmp_df.total - tmp_df.personal
all_personal, all_others = tmp_df.personal.sum(), tmp_df.others.sum()
tmp_df['chi2'] = tmp_df.apply(calc_chi2, args=(all_personal, all_others), axis=1)
tmp_df['frequent'] = tmp_df.personal * all_others > all_personal * tmp_df.others
return tmp_df[(tmp_df.frequent == True)
& (tmp_df.personal >= 5)].sort_values(by='chi2',
ascending=False).head(10)最後に、先の関数に渡すテーブルを作成するためのユーザー軸で絞る関数を書き、完了です。
def user_characteristic_emojis(user, emoji_df):
tmp_df = pd.concat(
[emoji_df[emoji_df.React == user].groupby('Emoji').size(),
emoji_df.groupby('Emoji').size()],
sort=False, join='inner', axis=1).rename(columns={0:'personal', 1:'total'})
display(get_top_emojis(tmp_df))ざっくりと手順を説明すると、下記のように動作するイメージです。
- tmp_df で絵文字ごと対象ユーザーの利用回数、他ユーザーの利用回数をテーブル化
- personal_all, other_all で対象&他ユーザーの全絵文字の合計利用回数を設定
- set_chi2 関数で各絵文字に対象ユーザーの利用頻度についてのカイ二乗値を算出
- 利用頻度が平均より高く5回以上使われた絵文字のうちカイ二乗値が高い絵文字上位を display 関数で表示
今回は最低頻度は5回に設定しました。これによって数回しか絵文字を使ってない場合でも他の誰も使ってない場合は「特徴的」と判断されてしまうことを避けようとしています。
さて、実際に関数を使ってみて、あらためて3者の「特徴的」な絵文字を見てみましょう!
user_characteristic_emojis('KSK', emoji_df)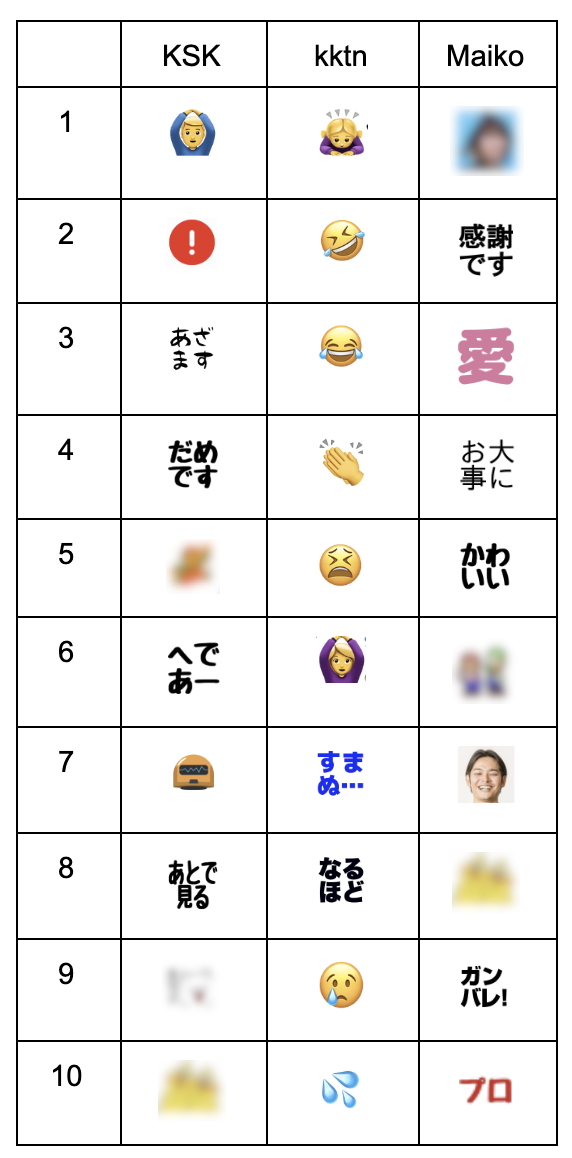
それぞれを知らない人に伝えられないのが残念ですが、だいぶ個々人の個性が出てきました。いいぞいいぞ。
このコードは簡単に応用ができます。ちょっとだけ切り口を変えるだけで(下記のように3行目のフィルタ条件を変えただけで)、ユーザー軸をチャンネル軸に変えることができ、チャンネルごとの特徴を見ることができます。「何らかの方法で絞った時」と get_top_emojis を汎用的に作ったのはこのためです!再利用!
def channel_characteristic_emojis(channel, emoji_df):
tmp_df = pd.concat(
[emoji_df[emoji_df.Channel == channel].groupby('Emoji').size(),
emoji_df.groupby('Emoji').size()],
sort=False, join='inner', axis=1).rename(columns={0:'personal', 1:'total'})
display(get_top_emojis(tmp_df))
channel_characteristic_emojis('general', emoji_df)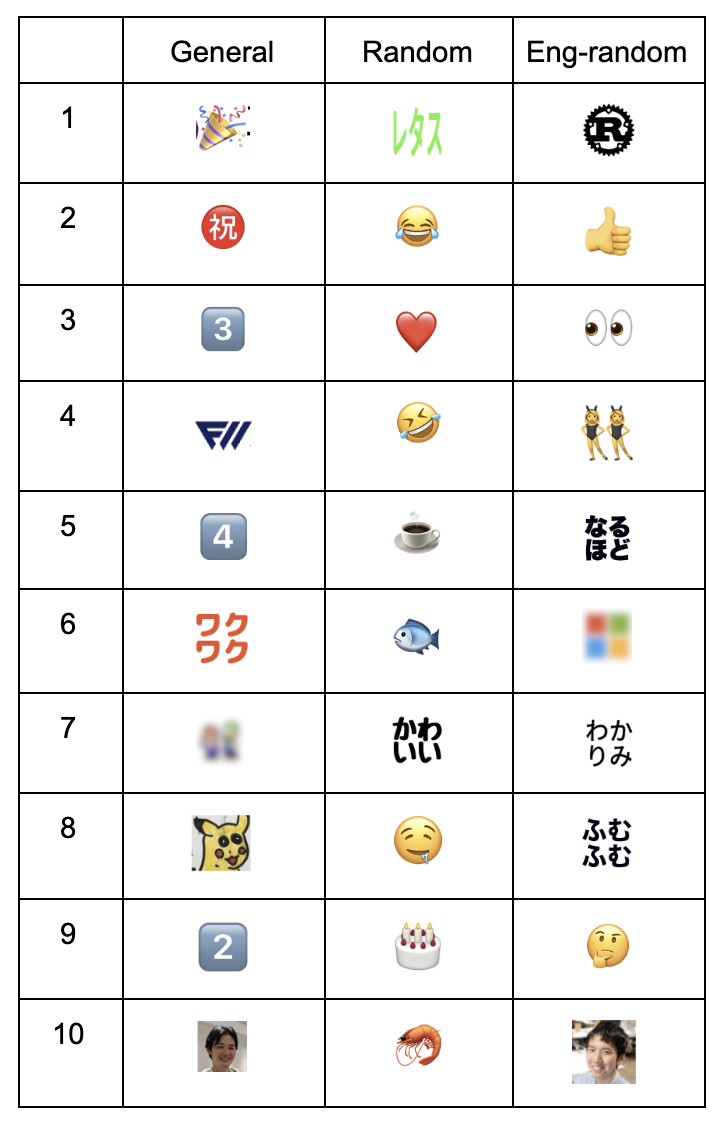
General (全社的なアナウンスと一般的な業務連絡)、Random (仕事に関係ない雑談と給湯室でのおしゃべり)、Eng-random (エンジニア関連の仕事に関係ない話) で違いを見てみました。Random のいい感じに仕事に関係なさそうな感じや、同じRandomでもエンジニア関連の方だと全然毛色が違ってエンジニアっぽい感じが良いですね。
同様にひと工夫を加えることで、絵文字ごとのTOPユーザーを算出することもできます。
def emoji_top_user(emoji, emoji_df):
tmp_df = pd.concat(
[emoji_df[emoji_df.Emoji == emoji].groupby('React').size(),
emoji_df.groupby('Emoji').size()],
sort=False, join='inner', axis=1).rename(columns={0:'personal', 1:'total'})
display(get_top_emojis(tmp_df))
emoji_top_user('clap', emoji_df)
全3回に渡る絵文字分析プロジェクト、試行錯誤しながら非常に楽しく絵文字と戯れることができました。今回の分析結果は本日よりメンバーに伝えていき、メンバーが少しでも楽しむことができれば良いなと思います。また、この投稿をキッカケに社内のコミュニケーションが一社でも、またほんの少しでも活発になり、「データを人々のエネルギーに」することができれば幸いです。
次回の私の投稿ではプロダクトマネージャーらしいブログを書くつもりなので、引き続きよろしくお願いいたします。
※お詫び
自分のありのままのコードを掲載予定でしたが、弊社内メンバーの優しい指摘を受けたため、せっかくなので修正して掲載しました。そのため自分の実力以上のコードとなっていることをお詫びいたします。